

Il New York Times fa causa a ChatGPT: la vera posta in gioco
|
|
 OpenAI risponde alle accuse del New York Times
OpenAI risponde alle accuse del New York TimesAggiornamento 10 gennaio 2024: Non solo davanti alla Corte distrettuale. OpenAI risponde anche sul suo blog ufficiale al New York Times, che l'ha accusato di violazione del copyright: secondo il NYT, strumenti come ChatGPT e Copilot genererebbero testi contenenti estratti dagli articoli pubblicati dall’editore, anche quelli accessibili solo dagli abbonati e protetti da metodi come un paywall.
In sintesi, OpenAI afferma che l'addestramento delle AI è considerabile come un fair use e che il "rigurgito" (cioè quando la AI ricopia parte di contenuti altri), di cui l'accusa il NYT, è un evenienza molto rara, in genere dipendente da una specifica richiesta dell'utente. Al riguardo, OpenAI accusa, anzi, il NYT di aver "manipolato i suggerimenti, spesso includendo lunghi estratti di articoli, al fine di far rigurgitare il nostro modello".
“Anche se non siamo d'accordo con le affermazioni contenute nella causa intentata dal New York Times, la consideriamo un'opportunità per chiarire la nostra attività, il nostro intento e il modo in cui costruiamo la nostra tecnologia”, scrive OpenAI. “La nostra posizione può essere riassunta in questi quattro punti, che approfondiamo qui di seguito: 1) Collaboriamo con le testate giornalistiche e creiamo nuove opportunità; 2) L'allenamento dell’intelligenza artificiale è fair use, ma forniamo un opt-out perché è la cosa giusta da fare; 3) Il "rigurgito" è un bug raro su cui stiamo lavorando per portare a zero; 4) Il New York Times non racconta tutta la storia”.
Rispetto all'ultimo punto, secondo OpenAI, il NYT avrebbe "intenzionalmente manipolato i suggerimenti, spesso includendo lunghi estratti di articoli, al fine di far rigurgitare il nostro modello". Prosegue OpenAI: "I nostri sistemi in genere non si comportano nel modo in cui sostiene il New York Times, e questo fa pensare che abbiano istruito il modello a rigurgitare o hanno scelto i loro esempi tra molti tentativi".
Rispetto al fair use: “L'addestramento di modelli di IA, utilizzando materiali Internet disponibili al pubblico, è fair use, come confermato da numerosi precedenti ampiamente accettati. Riteniamo che questo principio sia equo nei confronti dei creatori, necessario per gli innovatori e fondamentale per la competitività”. Ma ci si può sempre tirar fuori: “Siamo stati tra i primi nell'industria dell'IA a fornire un modo semplice per gli editori affinché neghino ai nostri strumenti la possibilità di accedere ai loro contenuti, e il New York Times lo ha adottato nell'agosto 2023”.
OpenAI ha definito le accuse del NYT “prive di fondamento”, augurandosi tuttavia di arrivare a un accordo.
Il 27 dicembre 2023 il New York Times ha portato dinanzi alla Corte distrettuale di New York OpenAI e Microsoft (quest’ultima quale partner avendo investito in OpenAI). Con l’atto di citazione in giudizio il NYT accusa le due aziende di aver addestrato i loro sistemi di intelligenza artificiale, cioè ChatGPT (poi inserito anche nei sistemi Microsoft come Copilot), su milioni di contenuti del quotidiano newyorkese, continuando inoltre ad attingere al materiale del giornale per fornire risposte agli utenti. Non si tratta della prima causa legale intentata contro i sistemi di intelligenza artificiale, già vari scrittori, attori e giornalisti hanno percorso la strada giudiziaria per difendere i loro diritti, ritenendosi danneggiati da questi modelli. Ma la causa del New York Times è la prima intentata da uno dei principali editori di notizie. Si tratta, quindi, per il peso dell’attore, di una iniziativa legale che potrebbe avere pesanti conseguenze sullo sviluppo dei sistemi di intelligenza artificiale e che sicuramente plasmerà il relativo mercato di riferimento.
La causa giudiziaria del New York Times a OpenAI
In sintesi, il New York Times chiede innanzitutto un risarcimento, non quantificato nello specifico ma solo genericamente, dell’ordine di miliardi di dollari di danni effettivi. Chiede altresì che i dati dei giornali siano espunti dai sistemi di intelligenza artificiale citati in giudizio, quindi la distruzione del set di dati utilizzato per addestrare la AI, cosa che potrebbe portare allo spegnimento delle attuali versioni della AI. Infine chiede che sia impedito a tali sistemi di accedere in futuro ai dati del giornale.
Nella citazione si menziona espressamente il pericolo che le “allucinazioni” prodotte dalle AI, mischiate ai dati presi dal giornale, possano mettere in cattiva luce lo stesso giornale, potendo gli utenti credere che gli errori delle AI siano in realtà imputabili al giornale. Inoltre, si paventa anche il pericolo che i sistemi di AI possano entrare in concorrenza con il giornale, in quanto gli utenti potrebbero limitarsi a leggere le notizie costruite dalle AI, senza passare quindi dal giornale medesimo. E questo, ovviamente, senza fornire alcun compenso al giornale. Il NYT conclude sostenendo che le due aziende hanno risparmiato miliardi, sfruttando senza compenso i dati del giornale, così evitando di “spendere i miliardi di dollari che il New York Times ha investito nella creazione di quell'opera, usandola senza permesso o compenso”.
La domanda alla quale dovrà rispondere la Corte distrettuale è, in sintesi, la seguente: premesso che le AI sono addestrate su enormi quantità di dati, laddove i set di dati più grandi (miliardi di pezzi di testo generati dall’uomo) spesso utilizzano materiali protetti da copyright in quanto sono generalmente contenuti di alta qualità, l’uso di tali dati è da considerarsi una violazione del copyright?
Le implicazioni sono ovvie: se la risposta è si, questo potrebbe ostacolare lo sviluppo delle AI negli Stati Uniti e nei paesi che adottassero lo stesso approccio, in quanto le aziende dovrebbero stringere accordi con i produttori di contenuti. E questo potrebbe avere delle ricadute di non poco conto. Non è solo un problema di costi, la selezione accurata dei dataset potrebbe finire per essere una barriera all’ingresso del mercato, per cui solo le grandi aziende potrebbero permettersi i costi dell’addestramento di una AI. Questo porterebbe a meno concorrenza nel settore.
Inoltre, data la difficoltà di stringere accordi con tutti, è evidente che le aziende produttrici di AI stringeranno accordi solo coi principali produttori di contenuti, i grandi editori, che quindi si ritroverebbero favoriti in questo nuovo mercato, a discapito dei piccoli produttori. Un po’ lo stesso effetto che si è riscontrato a seguito dell’introduzione, nella direttiva copyright, di un nuovo diritto a favore degli editori in base al quale le piattaforme del web devono compensare l’utilizzo degli estratti di news.
L’aspetto da non sottovalutare è che i paesi che adotteranno un approccio di questo tipo potrebbero trovarsi in svantaggio rispetto ad altri paesi che adottano un approccio differente. Ad esempio, la Cina potrebbe introdurre norme che autorizzano liberamente l’uso di dati anche soggetti a copyright, per l’addestramento delle AI. In tal modo si potrebbe realizzare un vantaggio per tali paesi. Il Giappone, ad esempio, ha già adottato questo approccio consentendo alle aziende l’uso di materiali protetti dal copyright anche senza necessità di autorizzazione. In questo modo si favorisce certamente lo sviluppo delle AI.
L’Unione Europea ha adottato un approccio differente, con la legge sull'intelligenza artificiale richiede agli sviluppatori di rivelare nel dettaglio quali materiali protetti da copyright sono stati utilizzati per l’addestramento della AI. In questo modo i detentori del copyright potrebbero avere un potere di azione nei confronti delle aziende. Però i dataset utilizzati inglobano quantità enormi di dati, per cui è piuttosto difficile quantificare quanto un creatore abbia contribuito e quindi stabilire l’entità del compenso.
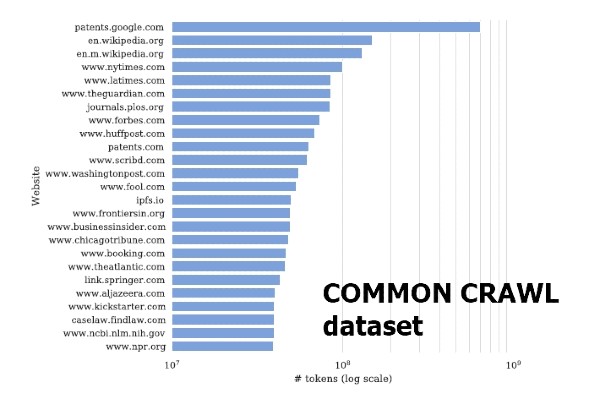
Il New York Times è stato in grado di dimostrare, almeno presuntivamente, la quantità di dati che OpenAI avrebbe utilizzato per il suo addestramento. Questo perché il dataset utilizzato da ChatGPT, cioè Common Crawl, espressamente indicato nella citazione del quotidiano statunitense, notoriamente ingloba testi che provengono da specifiche fonti, tra le quali il NYT che contribuisce per una percentuale specifica essendo la terza fonte immediatamente dopo Wikipedia e un database di brevetti statunitensi. È ovvio che una prova del genere sarebbe decisamente più difficile per un piccolo autore.
Un altro aspetto che non va trascurato è che stringere accordi con i grandi editori potrebbe portare a una visione ristretta da parte delle AI della società stessa, e quindi a pregiudizi culturali. In genere gli algoritmi soffrono già di pregiudizi, tendono a replicare su larga scala i pregiudizi che sono insiti nella società perché di fatto funzionano inglobando i dati della società che, prodotti da noi esseri umani, sono già intrisi dei nostri pregiudizi. Una AI che si limiti a usare per l’addestramento i dati dei principali editori potrebbe mancare dei dati, delle informazioni, e quindi dei punti di vista e delle opinioni delle minoranze della nostra società. Nella società moderna l’ampliamento del campo informativo ha determinato la nascita di una pluralità di fonti, alcune delle quali si occupano specificamente delle problematiche di minoranze e soggetti generalmente discriminati. Le grandi inchieste dei grandi editori, dovendo rivolgersi alla massa dei cittadini, invece, tendono a dare meno spazio a tali categorie, a fare, per così dire, un discorso più generale sfumando le particolarità sociali.
La concorrenza tra Intelligenza Artificiale e testate giornalistiche
Il problema sollevato dal New York Times non è solo lo scraping di contenuti dai giornali, cioè la sottrazione degli stessi senza compenso, raccogliendoli dai siti web o da altre fonti senza autorizzazione, ma piuttosto il fatto che tali sistemi tecnologici sono ritenuti ormai come potenziali concorrenti nel settore delle notizie. Il NYT asserisce con forza che se le testate giornalistiche non saranno in grado di proteggere il loro giornalismo si creerà un vuoto che nessuna AI potrà poi colmare: “Si produrrà meno giornalismo e il costo per la società sarà enorme”.
Negli atti depositati dal NYT troviamo molti esempi di presunte violazioni del copyright. Il New York Times cita un caso nel quale un utente ha chiesto espressamente alla AI di riportargli il contenuto di un articolo che si trovava dietro un paywall, quindi inaccessibile senza pagare l’abbonamento. E la AI ha riportato integralmente quel contenuto, evidentemente perché ne aveva l’accesso. Si tratta di una argomentazione molto suggestiva, ma in realtà il problema dovrebbe essere facilmente risolvibile. Consideriamo che le AI sono collegate ai motori di ricerca, se il motore di ricerca ha l’accesso ai contenuti lo ha anche la AI. Per evitare che un contenuto sia razziato dal Search Engine esistono specifiche direttive da inserire nei file robots sul server (per OpenAI è Disallow: GPTBot). Così come all’epoca delle accuse a Google News, i produttori di contenuti possono, volendo, bloccare l’accesso tramite apposite istruzioni. E infatti il NYT poco prima di avviare la causa ha provveduto a bloccare il bot di OpenAI, come possiamo verificare nel suo file robots. Non solo, il NYT ha anche modificato i suoi termini di servizio per vietare lo scraping, cioè la raccolta indiscriminata dei dati dai suoi siti per finalità di addestramento delle AI.
Ulteriormente il New York Times cita esempi di output di ChatGPT nei quali si trovano porzioni di articoli del quotidiano statunitense, compresa un’indagine vincitrice del Premio Pulitzer sul settore dei taxi di New York, indagine che ha richiesto 18 mesi per essere completata. Adesso ChatGPT e Microsoft Copilot, secondo il NYT, attingerebbero a piene mani a tale indagine fornendo una risposta all’utente del caso, senza che tale utente vada a leggere l’inchiesta sul sito della testata giornalistica americana. Per il NYT si tratta, evidentemente, di una appropriazione di contenuti, quindi una violazione del copyright.
Le argomentazioni portate dinanzi ai giudice sono molte, quello che possiamo dire è che, se siamo in presenza di una riproduzione esatta di contenuti protetti da copyright, sicuramente possiamo ritenere sussistente una violazione del copyright. Questo però accade raramente, e in genere è a seguito di una espressa richiesta dell’utente, come appunto nel caso citato dal NYT. Inoltre sicuramente è una violazione del copyright se la AI viene utilizzata per accedere a contenuti protetti dal copyright (ad esempio dietro paywall). È anche possibile che una violazione si generi nel momento in cui la AI utilizzi opere preesistenti per generare un suo output.
Ma il problema serio riguarda i dati utilizzati per l’addestramento. Se una AI si addestra utilizzando dati di terze parti, come spesso accade, si può considerare una violazione del copyright delle terze parti?
I modelli statistici GPT violano il copyright?
Il NYT ha sostenuto che i modelli GPT sfruttano e conservano ampie porzioni dell'espressione coperta da copyright contenuta negli articoli del giornale. In realtà la questione sta in termini piuttosto diversi, come abbiamo già detto.
GPT sta per trasformatore generativo pre-addestrato. Un modello GPT è molto differente da un Search Engine. Un motore di ricerca fa una scansione del web, crea un indice dei contenuti (quindi crea una copia cache dei contenuti) e utilizza l’indice per restituire i risultati pertinenti agli utenti in base alle loro domande (query). ChatGPT, invece, analizza la domanda (prompt) dell'utente e genera immediatamente un testo in risposta alla domanda, testo simile a quello che realizzerebbe un essere umano.
I modelli di AI orientati al linguaggio non fanno altro che utilizzare funzioni statistiche per produrre una continuazione ragionevole di un testo immesso in input. Cioè non sono fatti per ricordare dati, per quello ci sono i database, ma continuano il testo di input scrivendo quello che ci si potrebbe aspettare che qualcuno scriva dopo aver visto quello che le persone hanno già scritto considerando miliardi di altri testi. Ciò che fa ChatGPT non è altro che chiedersi statisticamente quale parola deve seguire l’input (il prompt), e poi lo stesso fa con la parola successiva, e così via fino a completare una risposta. Per capirci è simile ai motori di scrittura predittiva che completano le parole per gli utenti durante la digitazione sugli smartphone. Il modello GPT ha centinaia di miliardi di parametri per calcolare la probabilità della parola successiva.
Quindi i GPT non sono dei database, non contengono affatto il testo eventualmente utilizzato per l‘addestramento. Se i GPT lavorano su dati statistici, si può davvero affermare che il modello sta copiando qualcosa? Se non si tratta di un archivio strutturato, di contenuto strutturato, ma semplicemente di un interconnessione tra dati (in gergo neuroni) che hanno uno specifico peso dipendente dalla fase di addestramento, e che quindi elabora miliardi di dati al fine di produrre un output puramente statistico, possiamo parlare di violazione del copyright? Ovviamente non siamo in grado di dare un giudizio sul caso specifico del quale si occuperà la Corte distrettuale, e che dovrà analizzare nel concreto i casi portati in giudizio dal New York Times. Ma proviamo a ragionare sulla questione.
Opere derivate?
Per stabilire se ChatGPT viola il copyright dobbiamo verificare se copia l’opera originale. Qui dobbiamo scindere le fasi. È ovvio che in una prima fase l’opera originale viene copiata nella sua interezza (la violazione del copyright non si configura per la sola copia, ma in relazione all’utilizzo dell’opera, questo è un errore comune, spesso strumentalizzato proprio dall’industria del copyright in suo favore), ma poi subisce un processo di pre-elaborazione per rimuovere eventuali parti inutili o incomprensibili. Secondo le aziende di AI vengono rimossi anche i dati personali e parti soggette a copyright, anche se tale affermazione è difficilmente verificabile. Tuttavia, il testo originale, così elaborato, non è archiviato in un database, ma è solo fornito in input al software per la generazione di quello che poi diventa effettivamente il modello di AI. Il modello utilizza il testo per apprendere modelli e struttura della lingua, ma una volta terminato l’addestramento non richiede più il testo originale.
In tale prospettiva l'apprendimento automatico su cui si basa la generazione del modello potrebbe ricadere nell’ambito delle opere derivate, cioè quelle opere basate su una o più opere preesistenti. ChatGPT, infatti, non copia, bensì genera testo in base al contesto dell’input (qualsiasi risposta data da una AI è strettamente legata a quello che gli chiedete e ingloba in qualche modo sempre l’input) e agli schemi di frasi su cui è stato addestrato.
Se, quindi, siamo nell’ambito delle opere derivate, allora negli USA (per l’Italia la questione è piuttosto diversa, per questo si legga Mario Tedeschini-Lalli) si applica la dottrina del fair use. OpenAI ha appunto sostenuto che gli output di ChatGPT sono opere trasformative. Ovviamente sarà la Corte a stabilire se ciò è vero nel caso concreto, ma per stabilire se siamo in presenza di un’opera trasformativa occorre valutare i seguenti aspetti:
- Se la AI modifica in modo sostanziale l’opera originale;
- Se la AI utilizza l’opera originale per uno scopo completamente diverso rispetto a quello dell’opera originale;
- Se la AI aggiunge un valore creativo significativo all’opera originale;
- Se l’uso dell’opera della AI non va in concorrenza con il mercato dell’opera originale ma piuttosto crea un nuove mercato.
Il New York Times si oppone decisamente a questa lettura, e ci tiene a precisare che ChatGPT riprodurrebbe lo stile e il linguaggio dei propri articoli (questo perché ovviamente non esiste un copyright sui fatti e sulle notizie alla base degli articoli stessi). Ma il punto focale, secondo il NYT, sarebbe proprio l’ultimo dell’elenco sopra riportato. Secondo l’editore, infatti, l’output della AI potrebbe finire per soddisfare l’utente finale che non andrebbe più a leggere il giornale. In sostanza, secondo il NYT, l’output della AI finirebbe per entrare in concorrenza con l’articolo su cui si basa l’output. È un po’ lo stesso argomento che gli editori utilizzavano contro Google News. Su Google News si poteva leggere il titolo e un breve estratto dell’articolo (snippet), ebbene secondo gli editori quella porzione sarebbe stata sufficiente per indurre i lettori a non andare sul sito del giornale, che così perdeva i profitti degli annunci pubblicitari. Non era, e non è mai stato, un problema di “furto” di notizie, quella era la retorica apocalittica adottata dagli editori che non si sono mai realmente adattati alle tecnologie digitali. Il problema era che gli editori vedevano sfuggire un possibile guadagno perché qualcuno era in grado di sfruttare meglio di loro le tecnologie digitali, creando un prodotto (l’aggregatore) che era più appetibile (cioè fruibile) per il pubblico.
Con l’avvento delle nuove tecnologie i cittadini hanno preteso un qualcosa in più rispetto al passato, qualcosa di più facile da utilizzare rispetto al giornale classico. E gli aggregatori di news hanno offerto questo qualcosa in più, più facile, più veloce, più immediato. In presenza di una domanda di un servizio il mercato ha risposto con un’offerta più appetibile. È lo stesso che accadde all’epoca di Napster, quando il CEO di BMG, Middelhoff, sottolineò che il modello di business dell'industria del copyright non funzionava più, ma nessuno lo aveva capito o voleva capirlo. E quell’offerta oggi non è venuta dagli editori bensì dalle aziende tecnologiche, in primis Google e Facebook, che infatti sono riuscite a conquistare e monopolizzare il mercato emergente: la pubblicità online. Agli editori, rei di non essere stati in grado di adattarsi al nuovo, sono rimaste solo le briciole di quel mercato. Così come all’epoca l’offerta musicale legale venne da Apple (che assunse personale di Napster), non dall’industria del copyright.
Ma torniamo alla nostra domanda giudiziale. Una AI in realtà non conserva in sé i dati di addestramento, quindi le porzioni di testo. Durante il processo di addestramento, il modello viene esposto a enormi quantità di dati, ma alla fine del processo, i pesi del modello sono ciò che viene effettivamente memorizzato. I pesi rappresentano i parametri del modello che sono stati ottimizzati per fare previsioni o generare output basati sui dati di addestramento. Ciò vuol dire che non è possibile estrarre direttamente il testo originale dai pesi del modello. La struttura di una AI è tale che l’output è puramente statistico, il fatto che tale output sia molto simile a un testo specifico può essere semplicemente una conseguenza di una serie di fattori che così possiamo sintetizzare:
- -Diversità nei dati di addestramento: se il modello GPT è stato addestrato su un gran numero di testi scritti da specifiche persone è possibile che generi testo simile a quello di tali persone;
- Bias nei dati di addestramento: se i dati di addestramento contengono bias culturali, linguistici o di altro tipo, il modello può riflettere tali bias nei suoi output, come ad esempio nel caso in cui il modello sia stato addestrato su testi scritti da uno specifico gruppo demografico;
- Esempi specifici: se durante l'addestramento sono presenti esempi specifici di testi scritti da persone particolari, il modello potrebbe imparare a replicare quegli stili o contenuti;
- Overfitting: il modello potrebbe essere eccessivamente adattato ai dati di addestramento, così memorizzando particolari esempi del set di addestramento anziché generalizzare correttamente.
Ma in linea di massima la somiglianza potrebbe essere solo superficiale, e in alcuni casi potrebbe essere anche un’inferenza dovuta a bias di chi legge l’output del modello. Cioè, è teso a cercare parti comuni, vedrà parti comuni anche dove non ci sono. Ma ovviamente qui parliamo in generale, poi sarà la Corte a decidere il caso specifico. La Corte distrettuale dovrà esaminare la portata e lo scopo dell’uso dell’opera derivata, e in particolare l’impatto economico di tale utilizzo. Davvero l’opera di ChatGPT può essere tale da entrare in concorrenza con l’opera originaria? In linea di massima sembra difficile, anche considerato che ChatGPT è stato addestrato su milioni di opere, generalmente nel risultato dovrebbe essere difficile rintracciare porzioni significative di un’opera singola.
Facendo un ragionamento generale, però è possibile che ciò accada. Pensiamo ad esempio ad un utente che chiede a ChatGPT di creare un lungo racconto nello stile dell’autrice di Harry Potter, con gli stessi personaggi di Harry Potter. Una storia che l’utente potrebbe vendere al pubblico. Non dimentichiamo che, secondo gli stessi termini di servizio di OpenAI, l’opera data in risposta da ChatGPT in realtà appartiene all’utente che l’ha generata. E questo utente potrebbe guadagnare dei soldi sfruttando il lavoro di JK Rowling e ciò potrebbe avere un impatto negativo sull’autrice. Si può dire lo stesso per un singolo articolo di un giornale? Si farà una valutazione complessiva (tutti gli articoli del NYT) oppure sarà una valutazione basata sul singolo articolo? Questa è una scelta ideologica, il New York Times spingerà, ovviamente, per la prima direzione, OpenAI per la seconda.
Rilevanza culturale
In conclusione, la situazione è molto complessa. Sicuramente non è una banale disputa di copyright. La retorica apocalittica dei grandi editori, già utilizzata in passato quando attaccavano Google News e gli aggregatori di News, la ritroviamo pari pari oggi contro questa nuova tecnologia che minaccerebbe la società intera. Ma a ben vedere alla fine si tratta di una minaccia specifica ai loro interessi economici. Non dimentichiamo che le aziende di news sono aziende commerciali e come tali devono essere considerate. La loro retorica, però, già in passato ha fatto breccia nel legislatore portando alla creazione di un diritto del tutto nuovo inserito nella direttiva copyright europea, e ad una serie di iniziative che hanno coinvolto moltissimi Stati, tese a costringere le piattaforme del web a stringere accordi con gli editori per stabilire dei compensi a favore di questi ultimi. Eppure siamo sempre qui, con gli stessi problemi (il modello di business dei giornali che non funziona) e con gli stessi attacchi alle nuove tecnologie. È ovvio che quella iniziata dal NYT contro OpenAI non è altro che una appendice della stessa battaglia.
Varie aziende (The Associated Press e Axel Springer) hanno già stretto accordi con OpenAI per concedere in licenza l'archivio delle notizie. In base all'accordo, gli utenti di ChatGPT di OpenAI riceveranno riassunti di "contenuti di notizie globali selezionati" dai marchi mediatici. Le società hanno affermato che le risposte alle domande includeranno attribuzioni e collegamenti agli articoli originali. Il New York Times, invece, ha preferito bloccare l’accesso delle AI ai suoi articoli e portare in tribunale OpenAI. Non possiamo non notare che la decisione di bloccare il bot di OpenAI e quelli di altre AI del settore, quindi di impedire ai sistemi di intelligenza artificiale di accedere ai contenuti propri, non è una decisione semplice e priva di conseguenze, quanto meno per la grandi aziende come il NYT. Di fatto le AI sarebbero addestrate su dati di altre aziende, in tal modo si ridurrebbe l’impronta culturale di un sito o di un marchio. E se un domani i chatbot divenissero l’interfaccia utente principale per l’accesso a servizi e informazioni? È evidente che con una decisione del genere un’azienda sarebbe del tutto tagliata fuori. Provate ad immaginare un business online che nel 2002 avesse deciso di non essere indicizzato da Google.
In ultima analisi, i grandi editori si trovano in una situazione piuttosto difficile. Da un lato, stanno diventando sempre meno rilevanti, perché ormai le notizie grazie ad internet stanno diventando sempre più diffuse e le fonti di informazioni si moltiplicano. Ovviamente, in tal modo si moltiplica anche la disinformazione ma è una patologia ovvia in questo settore. Quindi hanno necessità di trovare nuove forme di monetizzazione. Dall’altro lato, però, non possono semplicemente chiudere la porta a quelle che promettono di essere le tecnologie più dirompenti nell'immediato futuro, pena la loro marginalizzazione culturale. Per questo vari editori esplorano differenti strade.
In quest’ottica il New York Times pone l’accento sulla “qualità” del giornalismo, sostenendo che è un elemento essenziale per la società nel suo complesso ma anche per i sistemi generativi. E che il metodo giornalistico è il vero discrimine tra un articolo di qualità e uno non di qualità. Qui è sotto gli occhi di tutti che esiste, purtroppo, una grossa fetta del giornalismo che non è di grande qualità, quel giornalismo che segue gli appetiti e le pulsioni del pubblico, cercando di stuzzicarle pur di ottenere visite e quindi profitti dalle pubblicità che infarciscono il loro sito.
L’impressione è che sia un problema di sopravvivenza di un settore, quello delle notizie, che è sempre più in crisi, e nonostante i tanti tentativi, spesso cercando la sponda del legislatore, non trova un modello di business che sia davvero convincente. L’impressione è che la torta sia sempre più ridotta, e quindi la sopravvivenza passi attraverso il consolidamento delle aziende del settore, espungendo dal mercato i piccoli per poter far sopravvivere i grandi. Purtroppo l’impressione è che accordi tra editori e aziende delle AI finirebbero proprio per portare a questo risultato.
Nulla ci dice, invece, che da tutto ciò ne uscirà qualche vantaggio per i cittadini. Di sicuro non si parlerà dei problemi etici delle AI, non si parlerà del fatto che questi strumenti così potenti sono sempre concentrati nella mani di poche aziende, non si parlerà del fatto che queste aziende sono praticamente tutte americane. Per i cittadini le cose probabilmente peggioreranno, come già detto ci sarà probabilmente meno concorrenza, nel mercato si introdurranno artificialmente barriere all’ingresso che favoriranno le aziende che si sono già inserite e ciò renderà più difficile l’ingresso di nuovi attori, specialmente se piccoli. Per i cittadini forse le AI saranno più limitate, casomai castrate per non violare il “copyright” dei giornali, e così via.
Con questa azione legale per la prima volta viene posto dinanzi ad un giudice una questione che orienterà il futuro della tecnologia. Stabilire se le risposte fornite da una AI ad un utente davvero entrano in concorrenza con la pubblicazione di un articolo sulla pagina web di un giornale. E cioè, in fin dei conti, la Corte distrettuale di New York dovrà stabilire quanto le AI saranno importanti nel futuro dell’intera società, quanta parte dei servizi passeranno dalle loro mani.




