

Algoritmi, intelligenza artificiale, profilazione dei dati: cosa rischiamo davvero come cittadini?
12 min letturaAlgoritmi tra identità e identificazione
Un algoritmo non è altro che un “procedimento che risolve un determinato problema attraverso un numero finito di passi elementari. Il termine deriva dalla trascrizione latina del nome del matematico persiano al-Khwarizmi, che è considerato uno dei primi autori ad aver fatto riferimento a questo concetto” (Wikipedia). La traduzione di un “algoritmo” in un linguaggio di programmazione consente di risolvere il problema tramite un computer. Così spesso tendiamo a riferirci, con detto termine, al codice che viene elaborato dal calcolatore.
Gli algoritmi, intesi in tal senso, sono il pilastro dell’economia basata sui dati, quella che tende a capitalizzare le informazioni degli utenti-cittadini, al fine di fornire servizi e prodotti agli utenti stessi, e quindi ottenere un profitto.
La necessità economica è, perciò, il motivo primario per l’uso di tecnologie basate sugli algoritmi. Queste tecnologie consentono, infatti, di fornire servizi personalizzati, e quindi a valore aggiunto: servizi migliori per il cittadino e risparmi per la comunità intera. Il tutto tramite procedure di identificazione degli individui.
Leggi anche >> I nostri dati: il petrolio dell’economia digitale
L’identificazione è qualcosa di diverso dall'identità. L’identità è il risultato di un processo personale di sviluppo attraverso anni di interazioni con altri individui. Ed è qualcosa di estremamente complesso. Potremmo definirla come una formazione di diversi strati. L’identificazione, invece, è un processo col quale, attraverso l’utilizzo di vari elementi, si procede al riconoscimento o alla classificazione di un individuo. L’identificazione si ferma solo ad uno, o a pochi, degli strati che compongono l’identità, così riducendo un complesso individuo in una forma monodimensionale. E questo è di per sé un problema.
Il processo di identificazione può richiedere, a seconda dei casi, un diverso grado di precisione. Ad esempio, per un acquisto online è indispensabile che il grado di precisione sia estremamente elevato. In molti casi, per una precisione accurata, si fa ricorso all’autenticazione, che richiede la partecipazione di una terza parte alla quale è affidata tale compito (es. firma digitale, eidas, SPID).
Per l’economia dei dati, però, non si richiede un tale livello di precisione. In genere le aziende del web non identificano fisicamente l’utente, ma si limitano semplicemente a classificarlo, cioè inserirlo in determinate categorie utili per l’invio di pubblicità personalizzate.
Intelligenza Artificiale e profilazione
La quantità di informazioni personali che, più o meno consapevolmente, diffondiamo ogni giorno è tale da poter alimentare gli “algoritmi” delle aziende del web, non solo quelle più conosciute, come Amazon, Google, Facebook e Apple, ma anche i Data Broker.
I Data Broker sono aziende che accumulano dati da numerosi fonti (anche offline) e li trattano correlandoli tra loro al fine di estrapolare nuovi dati. Con “Big Data” non si definisce tanto un grande insieme di dati quanto piuttosto l’operazione di trattamento automatizzato al fine di estrapolare nuove informazioni. L’applicazione classica dell’elaborazione algoritmica dei dati è la profilazione degli utenti al fine di inviare loro pubblicità personalizzata (targeted advertising).
È importante tenere presente che un individuo è identificabile in base alla sue relazioni, ma non è necessario conoscerne il nome (anche perché il nome legale, per la sua ambiguità, è un pessimo identificatore) o la locazione. Talvolta anche una serie di informazioni anonime (o anonimizzate) sono sufficienti per identificare, con maggiore o minore precisione, un individuo.
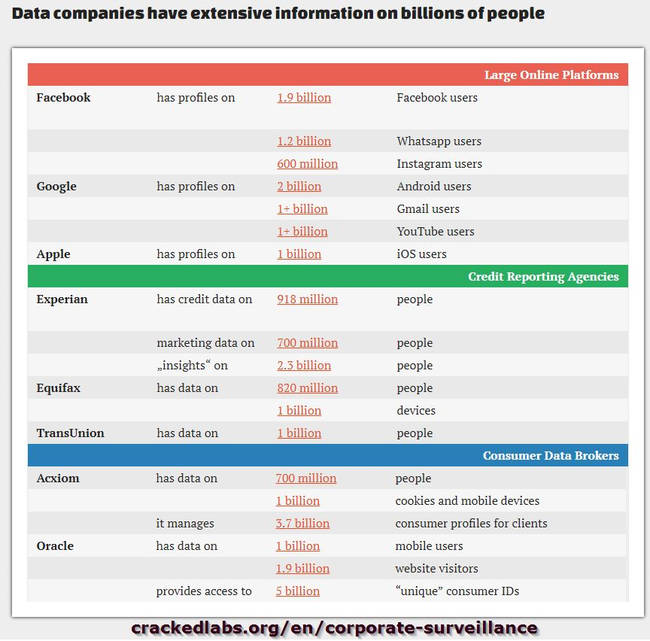
I Data Broker accumulano, quindi, informazioni da numerose fonti per estrarne correlazioni, cedendo poi i data base ricavati a terze parti (Aviva prevede i rischi per la salute individuale, come diabete, cancro, pressione alta e depressione, in base ai dati di consumo tradizionalmente utilizzati per il marketing acquistati da un data broker). Anche se spesso i dati sono anonimizzati, aziende come Acxiom, Experian, Datalogix, e tante altre sconosciute al grande pubblico, sanno di noi praticamente tutto, probabilmente più delle aziende del web (che generalmente si limitano all'accumulazione di dati dal web – ma Facebook acquisisce dati anche da altre aziende –). Questo perché sono in grado di unificare banche dati telefoniche, relative al credito, alle proprietà, alla localizzazione, alle vendite al dettaglio, alla navigazione online, ecc…, in un unico flusso digitale.
Per ulteriori informazioni sulla sorveglianza aziendali leggi il rapporto di CrackedLabs
Il termine “intelligenza artificiale” evoca ambientazioni fantascientifiche, con robot senzienti in grado di comprendere il linguaggio umano e di agire di conseguenza. Nella realtà una AI (Artificial intelligence) è un software complesso, programmato per prendere specifiche decisioni sulla base degli input ricevuti. Oggi, software di questo tipo non si limitano solo a giocare e vincere contro esseri umani (DeepMind di Google), ma determinano l’approvazione di un credito (Lenddo è una startup che utilizza i dati provenienti dai social media per valutare l’affidabilità finanziaria), offrono consulenza in materia assicurativa, guidano le auto, assistono clienti in procedure ripetitive, e prevedono le abitudini di acquisto. I processi decisionali sono sempre più automatizzati, e tali decisioni algoritmiche sono utilizzate in tutti i campi, anche nel settore pubblico, sanità e prevenzione dei reati, ad esempio.
AI, quindi, non è solo il machine learning, con computer che imparano gradualmente a riconoscere cose per poi elaborarle in modi sempre più complessi, ma anche l’elaborazione del linguaggio naturale, con il computer che impara a “sentire”; il riconoscimento delle immagini, con il computer che impara a “vedere”. I nostri stessi smartphone contengono sofisticati algoritmi di “intelligenza artificiale”, come Google Assistant, oppure Siri, o anche Alexa integrato nei dispositivi Amazon e Cortana in quelli Microsoft.
L’intelligenza artificiale è, quindi, un sistema decisionale, in base al quale si ottiene un risultato (decisione) sulla scorta degli input (dati) che alimentano l’algoritmo. Amazon, ad esempio, già utilizza l’AI per determinare le preferenze dei consumatori e suggerire prodotti agli acquirenti, ma anche per ottimizzare l'organizzazione dei magazzini. AI non è solo l’interfaccia parlante di Alexa, che sembra capire più o meno correttamente cosa gli diciamo ed agire di conseguenza, ma è molto di più e nello stesso tempo l’AI è anche qualcosa di molto più semplice, già presente da tempo nelle nostre vite.
La versione "invisibile" di reCaptcha di Google distingue tra esseri umani e bot.
Il termine utilizzato per descrivere l’approccio degli algoritmi per ricavare informazioni da dati raccolti in vario modo è Data Mining. Ogni qualvolta usiamo un computer, uno smartphone, un dispositivo connesso alla rete Internet, dei dati vengono raccolti, registrati, inviati a qualcuno per essere integrati in un vasto insieme di dati. Questo data base viene, appunto, algoritmicamente scansionato per estrarre (mining) correlazioni dai dati, al fine di ricavare dei modelli. Ad esempio per prevedere futuri acquisti.
E se la raccolta dei dati iniziali è generalmente soggetta a consenso (o comunque trova la sua legittimità in una base giuridica), i dati inferiti dalle correlazioni tra i dati iniziali non lo sono. Cioè, l’utente non ha la possibilità di sapere quali sono le informazioni che vengono estrapolate a seguito della correlazione. In realtà la stessa azienda che estrapola i dati spesso non è in grado di sapere esattamente quali dati verranno fuori dall'algoritmo, e in particolare non ha contezza dell’utilità di tali dati. Una particolarità del data mining sta proprio nel fatto che non è un’operazione limitata da una finalità specifica che finirebbe soltanto per limitare l’uso del data base di informazioni.
Il prodotto finale del data mining è la classificazione degli utenti, quella che normalmente definiamo come profilazione. Un profilo, infatti, non è altro che una lista di categorie determinate estrapolando informazioni dai dati raccolti con riferimento ad un individuo. In base al comportamento di tale individuo, a ciò che fa online, ma anche nella vita reale, si determinano delle categorie nelle quali egli può essere inscritto.
Ad esempio, gli “argomenti” di classificazione di Google li potete trovare (e gestire) nella pagina di impostazione degli annunci (https://myaccount.google.com/ → Impostazione annunci → Gestisci impostazione annunci).
Lo scopo della profilazione è l’inserimento di un individuo dentro determinate categorie che rappresentano una decisione. Le categorie, poi, possono essere combinate per realizzare un index score, ed eventualmente arricchite con dati demografici. Questo è un esempio di "identificazione".
Il problema non sta nella profilazione in sé, quanto piuttosto nel fatto che la classificazione è del tutto indipendente dalla volontà dell’individuo. Una persona può essere classificata come "maschio” o “femmina” (o entrambi in percentuale) in maniera del tutto indipendente da cosa egli è realmente.
Un “maschio” potrebbe tranquillamente essere classificato come “femmina” perché si rapporta con determinati siti allo stesso modo di altre femmine, e tale individuo non può in alcun modo modificare tale classificazione, essendo una classificazione interna, ad uso “marketing”, dell’azienda. All'azienda (Google, Facebook, ecc...) non interessa realmente come è un individuo, ma come si comporta e soprattutto come si rapporta con determinati siti.
Ad esempio, se cerchiamo il nostro nome e cognome sul motore di ricerca Google, quasi certamente otteniamo, a fine pagina di ricerca, la frase “Alcuni risultati possono essere stati rimossi nell'ambito della normativa europea sulla protezione dei dati”. Se invece cerchiamo “Rihanna”, tale frase non è presente. Perché?
Questo dipende dalla classificazione interna di Google per adempiere alla sentenza della Corte di Giustizia europea sul diritto all'oblio. Google ha algoritmicamente classificato tutte le persone in “famose” o “non famose”, laddove solo le seconde possono chiedere l'applicazione del diritto in questione (e ottengono la frase riportata sopra). Si tratta, però, di una classificazione interna di Google, algoritmicamente ricavata, e non modificabile da noi.
Chiaramente ogni forma di classificazione può portare anche ad errori. Se il computer di un utente viene usato da più persone (padre e figli), l’algoritmo tende a credere che la persona sia una sola. In ogni caso, la classificazione in base ad algoritmi non riscontra l’individuo effettivo come si estrinseca nella vita reale, quanto piuttosto un suo “doppio” virtuale, che può essere “maschio” ma anche “femmina”, “famoso” o “non famoso”, “giovane” o “vecchio”, con un disallineamento tra la vita reale e la vita basata sui dati (vita online o virtuale).
La profilazione è, quindi, un procedimento complesso, che non sempre consente l’identificazione fisica dell’individuo, anzi spesso non è assolutamente quello lo scopo. L’identificazione fisica è, invece, un obiettivo dei governi, nel momento in cui cercano di realizzare profili dei cittadini dai quali estrarre possibili pattern comportamentali, al fine di prevedere possibilità future di delinquere. Non è invece una finalità specifica delle aziende. Molte aziende, infatti, si limitano a classificazioni di persone per categorie, in modo da indirizzare le pubblicità degli inserzionisti.
Per capire meglio, una ricerca (query) in un database potrebbe dare come risultato l'identificazione di 'tutte le persone con un reddito alto che abitano in un determinato quartiere e che hanno almeno un autoveicolo di proprietà'. In tal modo si restringe il numero di individui ai quali inviare una certa pubblicità od offerta commerciale, massimizzandone il risultato.
A ciò occorre aggiungere anche che attualmente la veicolazione delle informazioni, in una cultura ostile all’idea di pagare per le notizie, è strettamente legata alla pubblicità, e quindi pure l’editoria deve necessariamente occuparsi di profilare i propri utenti.
E questo può avere delle applicazioni in moltissimi campi. Ad esempio, LexisNexis Risk Solutions, un data broker, fornisce un punteggio di salute calcolando i rischi e i costi sanitari sulla base dei dati di consumo, comprese le attività di acquisto.
Leggi anche >> Il capitalismo della sorveglianza
Discriminazioni e pregiudizi (bias)
Ma se la profilazione a fini pubblicitari tratta i cittadini-utenti solo per categorie, esiste comunque un rischio per i loro diritti?
L’intelligenza artificiale viene utilizzata per prendere sempre più decisioni in un numero sempre maggiore di campi, come ad esempio per determinare l’idoneità al credito, per stipulare contratti assicurativi, e così via. Capita che tali decisioni siano sbagliate. In genere si discute delle problematiche di tali tecnologie quasi esclusivamente come questioni tecniche.
Nel famoso video del 2009, HP Computers are racist, si sostenne che il software di rilevamento del volto non fosse in grado di seguire una persona di colore. L’azienda (qui la spiegazione), dopo aver analizzato il problema, chiarì che non era un problema “razziale”, ma semplicemente una questione di insufficiente illuminazione dello sfondo che determinava problemi di contrasto. Secondo HP il software aveva difficoltà a “vedere” persone di pelle scura.
In realtà un software non “vede”, ma umanizzando il software HP nascondeva il vero problema, e cioè che il software di fatto determinava, ovviamente non intenzionalmente, uno svantaggio per le persone di pelle scura. In sostanza non era “neutrale”. Quello che per l’azienda era un problema meramente “tecnico”, poteva però avere delle implicazioni nella vita reale sotto forma di discriminazione sociale.
Le forme di discriminazione ipotizzabili sono molte. Certe polizze assicurative potrebbero essere limitate in base al colore della pelle, al luogo in cui si vive; le migliori condizioni per le carte di credito potrebbero essere offerte solo a determinare persone e non ad altre; un negozio online potrebbe mostrare prezzi diversi per gli stessi prodotti in base alle caratteristiche individuali; un giornale online potrebbe mostrare titoli diversi a seconda delle persone (il Washington Post usa versioni diverse dei titoli degli articoli per testare quale variante ha prestazioni migliori); un prestito potrebbe essere rifiutato perché si hanno amici poveri sui social (Facebook ha depositato un brevetto per la valutazione del credito in base al rating degli amici sul social), e così via.
Una persona appartenente a una minoranza finirebbe per essere discriminata non tanto perché un impiegato di banca gli rifiuta un prestito, quanto perché l’offerta del credito non gli viene proprio fornita dal sistema che è alimentato da modelli discriminatori, che sono tali perché realizzati da persone che vivono in una società intrisa di preconcetti (bias), preconcetti che quindi replicano nei loro modelli.
Peter Haas e i bias degli algoritmi (spiegazione: tutte le foto dei lupi erano state scattate con la neve bianca sullo sfondo a differenza di quelle dei cani, così il computer aveva semplicemente imparato a identificare la neve, non i lupi)
Lo scorso autunno un professore dell’università della Virginia nota che un sistema algoritmico produceva risultati “sessisti”, associando alle donne immagini di cucina e così via. Per questo motivo ha analizzato gli input forniti alla macchina, verificando che due collezioni di immagini, tra cui una supportata da Microsoft e Facebook, presentava una distorsione di genere nella raffigurazione di attività come la cucina e lo sport: mentre le immagini di cucina, shopping e lavaggio erano associate a donne, quelle di sport erano legate ad uomini. Il software di apprendimento automatico in fondo non faceva altro che il suo lavoro: apprendeva. Erano gli “insegnanti” che avevano qualche problema.
Un software di apprendimento alimentato con input intrisi di pregiudizio non può che consegnare risultati anche essi intrisi di pregiudizio. Quindi, ad esempio, potremmo avere immagini di “uomini in cucina” che vengono etichettati come “donne”, semplicemente perché al software è stato insegnato che nella realtà in cucina ci sono le donne e non gli uomini.
Ma non solo. L’utilizzo di algoritmi con modelli predittivi è intrinsecamente conservatore, perché fondamentalmente non fanno altro che usare dati del passato per prevedere un comportamento futuro. E in certi campi, un comportamento che devia da quello passato potrebbe addirittura essere indice dell’avvio di un percorso delinquenziale o terroristico.
Data surveillance
Un profilo algoritmico può essere una tecnologia discriminatoria, in quanto tende a differenziare persone e gruppi, e in genere noi non abbiamo consapevolezza né del funzionamento degli algoritmi alla base né dei criteri di input del software. I dati forniti in input potrebbero essere non corretti, oppure incompleti, e non avendo accesso agli stessi non possiamo correggerli o modificarli. Ma, in particolare, il modello tradotto in software potrebbe esacerbare le disparità tra gruppi o individui. Come nel caso del software HP, il cui problema “tecnico” probabilmente derivava dal fatto che nel laboratorio la maggior parte dei dipendenti erano bianchi.
Dal momento che l'apprendimento automatico e l'intelligenza artificiale operano attraverso la raccolta, il filtraggio e quindi l'apprendimento e l'analisi dei dati esistenti, l’algoritmo finirà per replicare i pregiudizi strutturali esistenti a meno che non sia progettato esplicitamente per renderne conto e contrastarli.
E il problema, in fin dei conti, non sembra essere costituito tanto dalla macchina (l’algoritmo) ma dall’essere umano che addestra la macchina. Se si tratta di una persona con pregiudizi, c’è il rischio che tali pregiudizi siano trasmessi all’algoritmo. E l’algoritmo, che è fondamentalmente un sistema di input-output, fornirà immancabilmente risultati (decisioni) discriminatori. Anche se al programmatore sembrerà neutrale, perché non riconosce il proprio come un pregiudizio.
Quella forma di sorveglianza sui dati, che Roger Clarcke definisce Dataveillance, è un monitoraggio che non si estrinseca sugli individui ma solo sui nostri dati, che non ci riguarda come singole persone, ma come aggregati. Non siamo noi i “sorvegliati”, ma i nostri “doppi” digitali, decomposti e ricomposti in un continuo processo di integrazione e disintegrazione dei nostri dati.
I dati che Google (con DoubleClick acquisito nel 2007), Microsoft (con aQuantive) e Yahoo (con Right Media e Blue Lithium) e i tanti Data Broker semisconosciuti trattano da anni, sono in genere cifrati, anonimizzati e per lo più non-identificativi, per cui, secondo le leggi in materia non determinerebbero “rischi” per gli individui. Ma queste informazioni aggregate, anonimizzate e trattate per gruppi sono esattamente le stesse informazioni utilizzate dalle aziende per stabilire chi è “uomo”e chi è “donna”, chi è “progressista” o “conservatore”, e perfino dall’NSA e dalle autorità per stabilire chi è “terrorista”.
Ti serviremo annunci in base alla tua identità, ma ciò non significa che sei identificabile (Erin Egan, responsabile della privacy di Facebook , 2012)
E, mentre i partecipanti al dibattito sulla privacy e le stesse leggi in materia si focalizzano sulla tutela delle persone, e quindi dei dati identificativi, si tralasciano i rischi del trattamento delle informazioni anonimizzate e aggregate che, invece, appaiono essere estremamente importanti, e foriere di discriminazioni sui gruppi e sulle minoranze.
Immagine in anteprima via Theinforblog




