

Il business della pubblicità online incentiva contenuti di bassa qualità e l’uso spudorato dei nostri dati
13 min letturaIl 25 maggio 2018 sarà pienamente applicabile il regolamento generale per la protezione dei dati personali (GDPR). Lo scopo di tale regolamentazione europea è la tutela delle persone fisiche con riguardo al trattamento dei dati personali e alla libera circolazione di tali dati. Poiché il regolamento si applica a tutti i trattamenti di dati di cittadini residenti nel territorio dell’Unione, indipendentemente dalla sede dell’azienda che tratta i dati, anche le multinazionali dovranno conformarsi se vogliono servire i circa 500 milioni di cittadini dell’UE o gestire dati per una qualsiasi azienda europea. E le elevate sanzioni (fino a 20 milioni di euro o al 4% del fatturato annuo) non consentiranno più alle aziende di evitare di mettersi in regola basandosi sul fatto che i guadagni compensano ampiamente le multe.
L’industria più colpita sarà probabilmente quella pubblicitaria, in particolare tutte quelle aziende che utilizzano le informazioni sul comportamento dell’utente raccolte durante la navigazione online (ma non solo, spesso tali informazioni vengono incrociate con una miriade di altre informazioni raccolte anche dalla vita offline) per individuare gli interessi degli utenti e fornire annunci pubblicitari in base a tali interessi. La raccolta di dati, quindi, avviene non direttamente da parte dell’azienda (e il suo sito) bensì da una rete di siti partner. Ovviamente funzionano utilizzando cookie e tecnologie simili (detti marcatori in linguaggio tecnico) che consentono di identificare l’utente.
Tali modelli di business sono profondamente invasivi e pongono gravi problemi con riferimento al rispetto della privacy. Infatti, l’utente, per poter essere profilato nelle sue abitudini, ha il diritto di ricevere un’informativa sul trattamento dei dati, ha il diritto di sapere quali dei suoi dati vengono raccolti, come vengono trattati, e a quale fine. E solo dopo aver autorizzato (con un consenso espresso e non tacito) il trattamento, i suoi dati possono essere utilizzati a fini di profilazione. Occorre aggiungere che il consenso non può essere unico per tutte le finalità, ma deve essere distinto: serve un consenso per il trattamento dei dati a fini di sicurezza di un sito, uno per il trattamento a fini di ottimizzazione del sito (analytics), uno per la finalità di marketing e uno per la profilazione dei suoi dati.
Il problema si pone anche per il remarketing (o retargeting, dal nome che Google da al suo tool per fornire questo tipo di servizio). Per fare un esempio, se l’utente non conclude un acquisto su un sito di ecommerce, gli annunci pubblicitari del venditore seguono l’utente nella sua navigazione online, anche fuori del sito di ecommerce. Secondo gli esperti è un servizio con alto tasso di conversione, cioè spesso l’utente alla fine completa l’acquisto, anche se talvolta può sconfinare in una sorta di stalkeraggio.
Il remarketing è una forma banale di servizio pubblicitario, ma per capirne l’invasività possiamo pensare a un equivalente nel mondo reale di una persona che esce da un negozio con un cartello attaccato alla schiena che indica quali negozi ha visitato prima. Per la profilazione dovremmo aggiungere al cartello una quantità enorme di altri dati, compreso dati demografici e psicografici (che riguardano il comportamento e la personalità).
Partner e terze parti
Il problema principale sta nel fatto che la maggior parte di queste aziende non ha rapporti diretti con gli utenti (per questo vengono dette terze parti), ma raccoglie i dati tramite una miriade di siti collegati (partner). Con riferimento a Facebook, ad esempio, possiamo considerare i tanti siti che presentano i plugin sociali (ma non solo). Ma è importante tenere presente che non sono solo le aziende tipo Google e Facebook che utilizzano queste tecniche, ma anche gli innumerevoli publisher (editori). Anche loro raccolgono dati dei cittadini non solo tramite il sito principale (ad esempio, un giornale) ma anche tramite i partner.
Queste aziende basano generalmente le loro attività su un meccanismo di opt-out (cioè, tratto i tuoi dati fino a quando non mi dici di non trattarli più) che presenta numerose problematiche:
- Difetto di trasparenza, perché molto spesso i siti partner non forniscono informazioni adeguate sull’utilizzo dei dati da parte dei publisher, cioè quali dati essi raccolgono e a quali fini (il principio di trasparenza è uno dei pilastri fondamentali del GDPR).
- Obblighi sulla qualità dei dati, il GDPR prevede ulteriori obblighi a carico delle aziende, in tema di aggiornamento dei dati, diritto di accesso ai dati e portabilità, che aggraveranno sicuramente gli oneri delle aziende che operano quali terze parti.
- Il meccanismo di opt-out appare non essere più conforme alla normativa europea, che prevede un consenso che deve essere preventivo, non necessariamente esplicito ma sicuramente non tacito.
Queste aziende da tempo hanno iniziato ad analizzare la compatibilità delle loro attività col GDPR. Alcune ritengono che potrebbe essere valido un consenso basato su un comportamento attivo dell’utente. Ad esempio, se l’utente, dopo essere stato informato, continua a navigare sul sito (partner), tale comportamento potrebbe essere ritenuto un consenso valido (rispetto al trattamento dell’azienda terza parte). In realtà il GDPR, pur non pretendendo un consenso esplicito (se non per i dati “sensibili”), richiede comunque un consenso “inequivocabile” (unambiguous in inglese), per cui non deve sussistere alcun dubbio che col proprio comportamento l’interessato abbia voluto comunicare il proprio consenso. Cioè l’inerzia non è consenso valido, come anche form precompilati e caselle pre-selezionate. Viene da chiedersi se il semplice navigare un sito sia assimilabile a un comportamento “inequivocabile”, considerato che l’utente potrebbe semplicemente non aver letto l’informativa, ad esempio perché il banner non è così visibile sul sito (attualmente occorre un banner che rinvia all’informativa estesa). Sicuramente non basta il mero scrolling della pagina.
Un’altra strada valutata è quella dei legittimi interessi del titolare del trattamento da utilizzare, al posto del consenso, quale base giuridica del trattamento dei dati. In tal caso sarebbe sufficiente chiarire che il sito utilizza cookie/identificatori a scopo pubblicitario, raccoglie dati e li adopera al fine di mostrare annunci ai visitatori interessati ai prodotti in base al loro comportamento di navigazione passato. Nel caso di trattamento basato sui legittimi interessi occorre comunque dare la possibilità all’interessato di opporsi al trattamento (tramite opt-out).
Questa possibilità, però, non è così pacifica. Non è sufficiente che il titolare abbia la necessità di elaborare il dato a fini propri o di terzi, ma occorre bilanciare gli interessi del titolare con quelli dell’interessato. Insomma, non basta che l’interesse sia “prevedibile” da parte dell’utente per ritenerlo legittimo (l’industria sostiene che la stragrande maggioranza degli utenti è a conoscenza della pubblicità personalizzata e preferirebbe annunci mirati). L’esempio comune è quello del trattamento dei dati per finalità di marketing diretto, cioè se l’interessato è già cliente dell’azienda è legittimo aspettarsi che abbia interesse a ricevere comunicazioni da parte del venditore col quale intrattiene già rapporti commerciali. Caso ben diverso, però, è se l’interessato non ha alcun rapporto commerciale con l’inserzionista. E, in particolare, qui discutiamo di una situazione nella quale un utente naviga un sito partner, quindi diverso da quello dell’inserzionista (terza parte).
Altri publisher tentano la strada dell’anonimizzazione dei dati (es. Perimeter), utilizzando solo dati aggregati e quindi non soggetti a consenso. Ovviamente occorrerà valutare attentamente la qualità dell’anonimizzazione prima di dare un giudizio. Ma occorre rimarcare che il tracciamento degli utenti non sembra essere mai realmente anonimo (secondo lo studio De-anonymizing Web Browsing Data with Social Networks nel 70% dei casi è possibile identificare un individuo sulla base della sua navigazione “anonima”). Molti editori sostengono che non trattano dati personali perché non rilevano nome e cognome, precisando che usano “solo” identificatori “anonimi” di dispositivo. Ebbene l'identificatore di dispositivo è spesso più identificativo di tanti nome+cognome, e quindi è assolutamente un dato personale da tutelare in modo rigoroso.
Insomma, l’impressione è che la situazione per gli inserzionisti, i publisher, i siti di terze parti che raccolgono dati tramite siti partner, col GDPR si farà piuttosto difficile. La raccolta dei dati tramite siti collegati appare sempre problematica perché spesso poco trasparente. È vero che oggi molti utenti sono consapevoli dell’esistenza delle tecnologie di profilazione, ma hanno una scarsa consapevolezza di quali dati vengono raccolti e che fine fanno davvero i loro dati.
Col GDPR queste aziende dovranno portare alla luce in qualche modo il loro modello di business. Solo così questo modello diverrebbe compatibile col regolamento europeo. Ma è abbastanza facile prevedere che un certo numero di utenti potrebbe non concedere il consenso al trattamento dei propri dati nel momento in cui viene informato (come è d’obbligo) che i dati sono ceduti a terze parti (studio IAB).
Programmatic advertising
La pubblicità nel mondo digitale si è evoluta. Prima non era personale, ma rivolta a gruppi definiti dai mass media che la gente guardava (TV), leggeva (giornali), o ascoltava (radio). L’inserzionista sponsorizzava direttamente quel media perché voleva raggiungere un certo tipo di lettore, spettatore, o ascoltatore, al quale piaceva un certo tipo di giornale, programma TV o stazione radio.
Oggi siamo di fronte a qualcosa di completamente diverso, che viene definito programmatic advertising (o AdTech). L’Adtech è una tecnologia basata su un software che automatizza e velocizza il processo di acquisto e vendita degli annunci, portandolo ad un livello di efficienza impossibile per gli essere umani, e offre agli inserzionisti la possibilità di incorporare grandi quantità di dati (demografici, psicografici, comportamentali) da più fonti (i siti partner, offline...), per offrire annunci sempre più pertinenti e personalizzati.
Gli inserzionisti hanno i loro dati proprietari, che ricavano da fonti proprie (mail dei clienti, i prodotti acquistati, valore medio degli ordini), che fondono con i dati proveniente da altre fonti, cioè i Data Broker, quali Acxiom, Datalogix, Experian, ecc… I Data Broker in genere hanno dati relativi agli acquisti, credit score, reddito familiare e dati demografici.
Gli inserzionisti possono, quindi, sulla base di tali dati, selezionare un segmento di pubblico (profilazione). Se il cookie, o l’identificatore (quello caricato sul dispositivo dell'utente) corrisponde ai criteri selezionati dall’inserzionista, il sistema di acquisto degli annunci farà automaticamente un’offerta per l’annuncio (una certa quantità di impressioni). È il Real Time Bidding (RTB), perché il tutto avviene in tempo reale. Ma, se tutto avviene in pochi secondi, come sarà possibile spiegare all’utente in anticipo dove finiscono i suoi dati e chi li utilizzerà?
Dal 2015 la AdTech è il tipo dominante di pubblicità.

I nostri dati sul mercato digitale
Con la AdTech le pubblicità seguono le persone, tracciandole incessantemente per esporre le loro vite al mercato dello scambio di annunci (gli Ad Exchange). Gli utenti vengono etichettati tramite cookie e identificatori, equivalenti a veri e propri spyware installati sui loro dispositivi spesso senza nemmeno che l’utente ne sia a conoscenza. Il risultato è qualcosa che sembra la pubblicità vecchio stile, ma di fatto è una parente strettissimo dello spam, la posta indesiderata.
L’inserzionista ha un controllo scarso o inesistente sulla sua pubblicità, la condizione è che l’annuncio sia distribuito in base a una segmentazione della popolazione, per questo capita spesso che le inserzioni finiscano lì dove non c’è nemmeno una notizia, un prodotto, ma semplicemente quello che oggi si etichetta come “fake news”. L'incentivo non sta più nel produrre contenuti di qualità, quanto nel produrre storie originali e sensazionalistiche, assicurandosi che diventino virali, generando così un traffico enorme. Le "fake news", come l'abbassamento della qualità dei contenuti, sono il prodotto dell’economia del programmatic advertising.
Tantissime persone hanno capito come funziona il sistema e come utilizzarlo per fare soldi. Gli annunci seguono le persone, quindi è più utile costruire un titolo e un articolo sulla persona, che legare un annuncio ad una notizia, più si solleticano gli istinti del pubblico, più diventa facile ottenere visualizzazioni, annunci, soldi. Certo, è possibile mettere in blacklist il sito x e il sito y, ma il problema rimane e nessuna regolamentazione delle "fake news" lo modificherà. Anzi, si aggrava progressivamente perché i giornali più “seri”, per poter sopravvivere, sono costretti a competere sullo stesso campo, con titoli sempre più “strillati” e articoli sempre meno distinguibili dalle “fake news”. L’AdTech paga chi raggiunge i target (le persone), non la qualità della notizia.
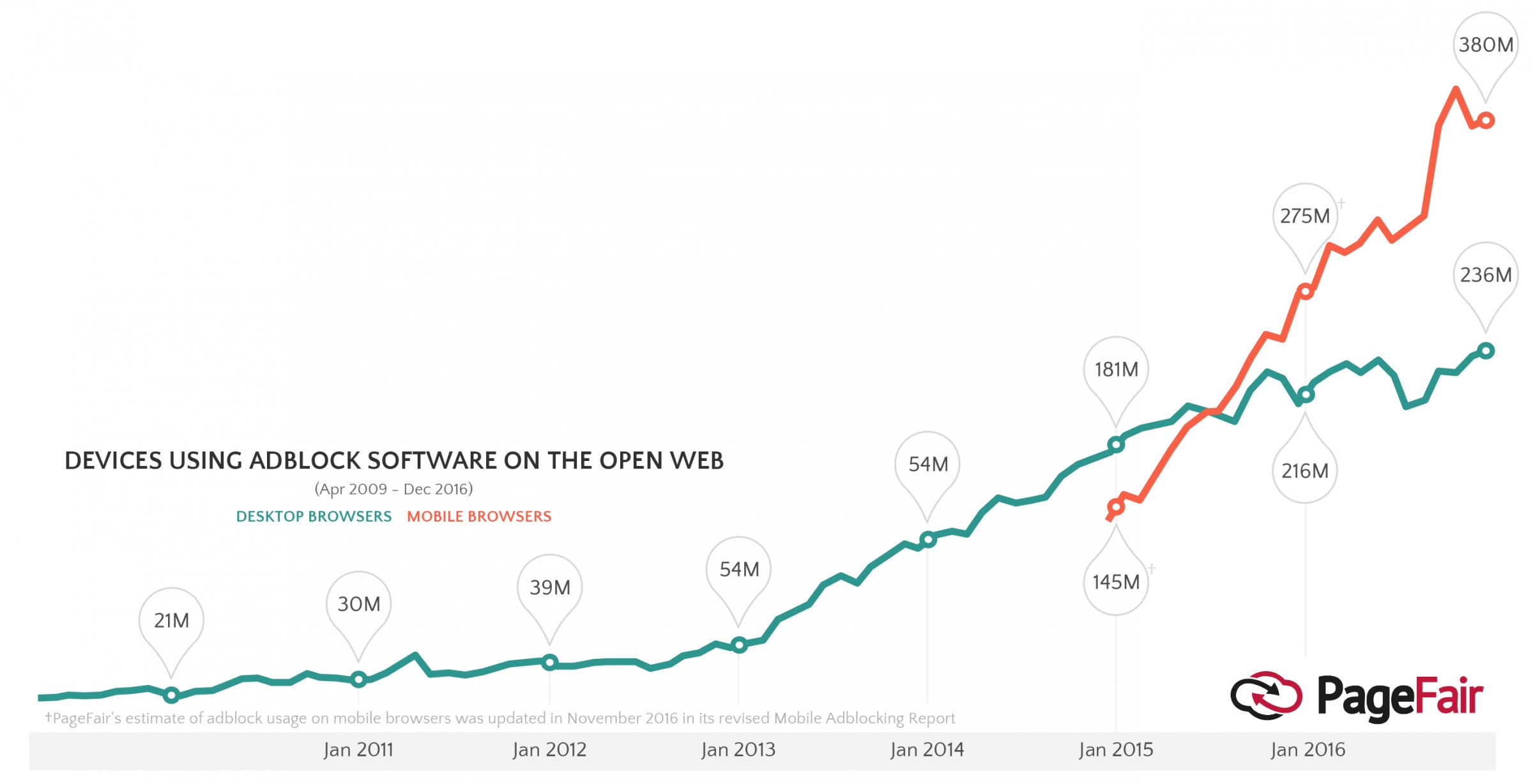
Da tutto questo sempre più gli utenti cercando di difendersi. Secondo un rapporto di PageFair del febbraio 2017 almeno l’11% degli utenti utilizza dei software per il blocco degli annunci pubblicitari (es. AdBlock), e questa cifra è in crescita. Tantissimi utenti utilizzano sistemi simili che non bloccano direttamente gli annunci ma impediscono il tracciamento da parte di terze parti (es. Privacy Badger). L’effetto è simile: impedire la pubblicità programmatica. Secondo GlobalWebIndex il 22% degli utenti di dispositivi mobili blocca la pubblicità, ma le percentuali sono in crescita. Nel rapporto si sostiene che c’è una domanda crescente per strumenti adatti a bloccare le pubblicità: 1 utente su 3 si lamenta della quantità eccessiva delle pubblicità e della loro invadenza,
Those blocking ads in the US are most likely to be “frustrated”, blocking ads because they take up too much screen space, are annoying, intrusive or because there’s simply too many of them (dal rapporto GlobalWebIndex)

Quel malware chiamato pubblicità
Se le cifre cresceranno allo stesso ritmo (ma le evidenze suggeriscono che la crescita sarà molto più veloce), saremo in presenza del più grande boicottaggio che la storia dell'umanità abbia mai visto. È evidente che la pubblicità online, per come è strutturata oggi, provoca negli utenti sentimenti piuttosto simili allo spam. E l’industria della pubblicità, invece di preoccuparsi di questa situazione, e di prendere atto che c’è una forte domanda di qualcosa di diverso, di meno invasivo, di più tutelante per gli utenti, cosa fa? Inizia una guerra contro i software di AdBlock. L’industria dell’AdTech vuole eseguire del codice sui dispositivi degli utenti, codice che invece gli utenti non vogliono eseguire. È esattamente la definizione di “malware”.
Nel 2015 è Yahoo ad attivarsi contro gli AdBlock, nel 2016 Facebook inizia la sua personale battaglia contro AdBlock Plus, nel frattempo si muovono anche gli editori. Il passo successivo è portare il caso in un’aula di giustizia. Sono tanti i giornali (RTL Interactive, ProSiebenSat.1, Süddeutsche Zeitung) e gli editori (Axel Springer) che fanno causa ai produttori di software di blocco pubblicità. Nel 2017 arrivano le prime sentenze, la corte d’appello di Monaco in Germania accoglie le richieste di Adblock Plus: è un diritto dei consumatori quello di bloccare le pubblicità indesiderate.
La corte d’appello di Monaco raccomanda agli editori di concentrare le proprie energie sulla ricerca di un modello di business alternativo. Il 19 aprile 2018 la Corte Suprema tedesca conferma il provvedimento (tweet di AdBlock).
La sentenza della Corte Suprema precisa qualcosa che dovrebbe essere di solare evidenza, e cioè che anche se un editore ha il diritto di combattere per il suo business (ormai basato esclusivamente sulla pubblicità), questo non vuol dire che debba prevalere sui diritti del cittadino. Cioè, per poter sopravvivere un editore non può imporre ad un cittadino come usare il suo smartphone, non può imporre ad un cittadino di vedere le pubblicità, un cittadino ha il diritto di dire no.
E quindi torna alla mente l’altra battaglia che si combatte da anni, senza esclusione di colpi, la guerra del copyright, una guerra tra l’industria e i cittadini, una guerra che ha portato l’industria a fare causa ai suoi stessi utenti, una guerra ancora in corso e che se fosse vinta dall'industria del copyright porterebbe a conseguenze gravissime sulla libertà di manifestazione del pensiero e i diritti dei cittadini in genere.
Chi si conforma al GDPR?
Però, col GDPR qualcosa cambia. Lo scandalo Cambridge Analytica mette in evidenza i problemi del modello di sfruttamento dei dati, e addita Facebook come il cattivo di turno. Ovviamente non è così, Facebook è solo uno dei tanti che sfrutta i dati degli utenti, ma è il più visibile agli occhi dei cittadini, il più "temibile" almeno agli occhi degli editori, che, a mio avviso, stanno approfittando di questo scandalo per calcare la mano, per approntare una campagna di stampa che focalizza l’attenzione sul social in blu, nascondendosi all’ombra dello scandalo. L’intento non è certamente la tutela dei diritti dei cittadini, quanto togliere potere negoziale a Facebook in modo che gli editori possano contrattare a un livello di maggiore equilibrio con le piattaforme del web, casomai con la sponda dei governi.
Leggi anche >> Su Facebook e Cambridge Analytica abbiamo un problema di copertura mediatica
Sull’onda dello scandalo, Facebook stessa si affanna a introdurre profonde modifiche al suo sistema di sfruttamento dei dati degli utenti, annunciando una conformità al GDPR (non è qui la sede giusta per valutare se sia effettiva o meno), introducendo una serie di nuovi strumenti per i cittadini. Si tratta di modifiche ancora in divenire, ma dalle prime avvisaglie possiamo notare una maggiore trasparenza, e la possibilità di bloccare il targeting degli annunci in base ai dati raccolti dai siti partner (quelli coi pulsanti social). Nel contempo Facebook, con un annuncio sul suo blog, avvia la chiusura dei rapporti con i partner (Data Broker).
Ma Facebook è solo l’ultimo della fila. Le grandi piattaforme del web hanno già iniziato a smarcarsi dagli inserzionisti, per non trovarsi col cerino in mano. Apple, ad esempio, già da tempo ha modificato il suo browser Safari imponendo restrizioni al tracking delle terze parti. Gli inserzionisti, attraverso le loro associazioni, hanno protestato verso tale scelta unilaterale, sostenendo che in tal modo gli utenti non riceverebbero più annunci personalizzati. In realtà il timore è di perdere profitti (la perdita stimata è tra il 10 e il 20%), visto che comunque potrebbero inviare pubblicità generica.
Poi, anche Google ha cominciato a regolamentare la pubblicità tramite un ad-blocker inserito nel suo browser Chrome.
Schiavi della pubblicità
L’AdTech viola la privacy, è difficile da controllare, è vettore di frodi e di malware (i provider di adtech non supportano né richiedono la cifratura del traffico), incentiva le pubblicazioni di notizie false, mischia volutamente pubblicità con notizie confondendo sempre più il confine tra le due, incentiva l'originalità piuttosto che la qualità, porta ad avere più contenuti usa e getta con scarsa attenzione alla qualità, mira a polarizzare il suo pubblico offrendogli contenuti tali da poter brandire contro gli "altri". Nel frattempo le pubblicità per le aziende sono sempre più scritte come fossero articoli e inserite nel flusso a confondere maggiormente la situazione.
Ciò che veramente conta è la viralità, perché è quella che porta a fare soldi, ma la viralità, i contenuti viscerali, quelli polarizzanti, le fake news, minano la fiducia nei giornali. È un circolo vizioso, è un business che ormai per sopravvivere è costretto a remare contro se stesso.
L’AdTech è il vero cancro dell’ecosistema digitale perché incentiva il contenuto piuttosto che il vero giornalismo. Perché affannarsi a cercare una notizia, a fare un'inchiesta, se è molto più semplice inventarne una?
La soluzione ovvia per i giornali sarebbe tornare alla pubblicità generica, ma ormai siamo abituati da anni a un rapporto asimmetrico tra gli editori (publisher) e i cittadini. Che tecnicamente viene definito server-client, ma la dizione più corretta è “master-slave”. Perché il potere sta tutto lato server (editori), perché questo modello di business impone agli utenti come usare i propri computer e smartphone, e prevale sui diritti dei cittadini.
Col GDPR, però, questo rapporto asimmetrico potrebbe cambiare definitivamente, e dare più potere ai cittadini. Forse è arrivato il momento di guardare ad altri modelli di business.




