



AI e responsabilità: la soluzione non è fermare la tecnologia, ma darle una regolamentazione
|
|
Premessa
La prima parte dell’articolo presuppone concetti complessi che sono, per necessità di sintesi e di contenimento della lunghezza dell’articolo, soltanto accennati. Per una disamina più approfondita si consiglia di leggere il seguente articolo: “Dal cervello predittivo alle AI generative”.
Capire il cervello per regolare l’AI
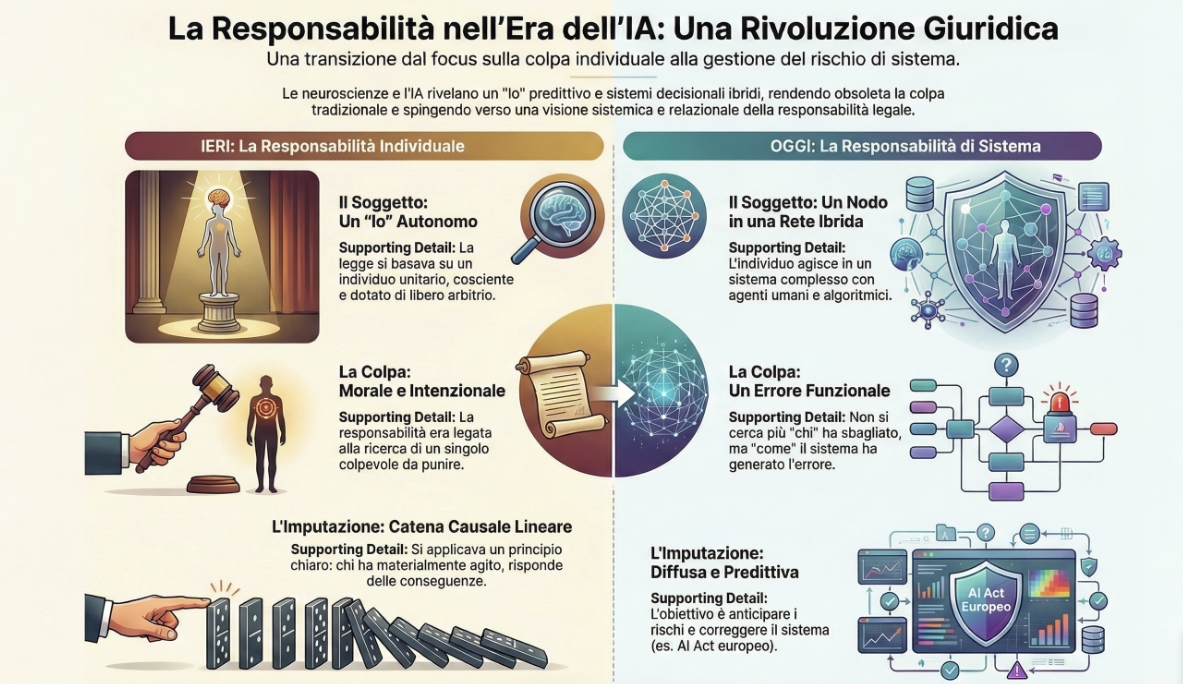
Questo articolo affronta un tema apparentemente tecnico - la responsabilità giuridica nell’era dell’intelligenza artificiale - ma lo fa a partire da una premessa radicale: non possiamo regolare bene ciò che non capiamo profondamente. E ciò che dobbiamo capire non è solo “come funziona l’AI”, ma come funzionano i sistemi cognitivi - umani, artificiali e soprattutto ibridi - che prendono decisioni nel mondo reale.
Quando il Parlamento Europeo ha discusso di attribuire “personalità elettronica” alle AI, o quando ha costruito l’AI Act sul principio di “supervisione umana”, ha implicitamente preso posizione su questioni filosofiche profonde:
- Cos'è un agente?
- Dove risiede la volontà?
- Come si distribuisce la responsabilità in un sistema complesso?
Ma se quelle posizioni sono basate su un’ontologia superata – cioè l’idea cartesiana di un “io” unitario, autonomo, trasparente a se stesso - allora rischiamo di creare norme strutturalmente inadeguate. Leggi che cercano il colpevole dove non c’è un centro decisionale, che impongono controllo umano dove l’umano non può materialmente comprendere, oppure che ignorano responsabilità sistemiche perché distribuite e non localizzabili.
Prendiamo il caso di un’AI che discrimina minoranze etniche nelle decisioni di credito. Il problema non è che qualcuno ha programmato la discriminazione. Il problema è che:
- L’AI è stata addestrata su dati che riflettono secoli di discriminazioni storiche;
- L’AI ottimizza metriche che, pur neutre in apparenza, amplificano pattern distorti;
- L’AI opera in contesti dove certi gruppi hanno meno accesso a “segnali positivi”.
Confrontiamo tutto questo con un caso umano. Gli studi sugli shooter bias mostrano che agenti di polizia, in simulazioni realistiche sotto stress, tendono a “predire” armi nelle mani di soggetti di minoranze etniche con frequenza maggiore rispetto a soggetti bianchi. È per malafede, o perché il loro sistema predittivo - esattamente come descritto da Andy Clark e Anil Seth - assegna pesi sbagliati alle aspettative culturali?
La somiglianza non è casuale: cervello umano e AI sembrano operare secondo logiche predittive strutturalmente analoghe:
- Costruiscono modelli del mondo basati su pattern passati;
- Minimizzano l’errore di predizione aggiustando pesi interni;
- Possono “allucinare” (vedere minacce inesistenti) quando i pesi sono mal calibrati.
Quindi, se non capiamo che la cognizione - umana e artificiale che sia - funziona così, rischiamo di commettere errori fatali:
- Sovrastimare il controllo umano, cioè imporre “human oversight” senza chiedersi se l’umano può effettivamente comprendere il sistema, come se bastasse avere qualcuno che controlla per garantire decisioni giuste - ignorando che anche il supervisore umano opera per predizioni e bias;
- Cercare colpevoli individuali in sistemi distribuiti, per capirci, punire l’ingegnere per un output emergente non prevedibile è come punire qualcuno per aver sognato: l’azione è emersa da una rete complessa, non da una volontà unitaria;
- Ignorare le possibilità di intervento strutturale, cioè, se il problema è nei “pesi di precisione” (umani o algoritmici), la soluzione non è moralistica ma tecnica: ricalibrare predizioni, modificare dati di training, ridisegnare metriche di ottimizzazione, introdurre feedback correttivi.
Leggere l’articolo citato in premessa è importante perché non si tratta di sola teoria, ma spiega perché il cervello funziona, forse, come una macchina predittiva (Clark, Friston, Seth), perché il “sé” è un modello distribuito e non una sostanza (Metzinger), e perché il confine uomo-macchina è funzionale e non ontologico (Haraway).
Non si tratta di esercizi filosofici astratti. Sono premesse operative per capire dove attribuire responsabilità in sistemi ibridi, per progettare training efficaci (per umani) e audit significativi (per AI), e per evitare regolamentazioni che creano illusioni di controllo senza migliorare gli esiti.
La vera sfida non è fermare la tecnologia, né difendere l’umano. È costruire un ecosistema normativo che riconosca la natura predittiva, distribuita e ibrida dei sistemi decisionali contemporanei complessi - e che governi i processi, non solo gli individui. Questo articolo mostra come il diritto europeo stia tentando questa transizione. E perché, senza le basi filosofiche giuste, rischi di fallire.

La responsabilità giuridica ai tempi dell’AI
Nella visione moderna, di matrice cartesiana, la responsabilità giuridica è fondata sull’unità e sull’autonomia del soggetto. “Io” sono responsabile perché sono un centro di azione coerente, in grado di prevedere e controllare le conseguenze delle mie azioni.
I recenti sviluppi delle nuove tecnologie digitali - gli algoritmi, ma in particolare l’intelligenza artificiale - hanno posto in dubbio questo principio. Andy Clark, nel suo libro “The Experience Machine: How Our Minds Predict and Shape Reality” (2023), sostiene che il cervello umano non sarebbe un mero ricevitore passivo di stimoli sensoriali, ma una macchina di predizione che costruisce costantemente un modello del mondo. Ogni percezione, pensiero o emozione nascerebbe da un’ipotesi del cervello su ciò che sta accadendo fuori e dentro di noi. Quando la realtà sensoriale non corrisponde alle previsioni, si genera un “errore di predizione”, che serve a correggere il modello interno per renderlo più accurato.
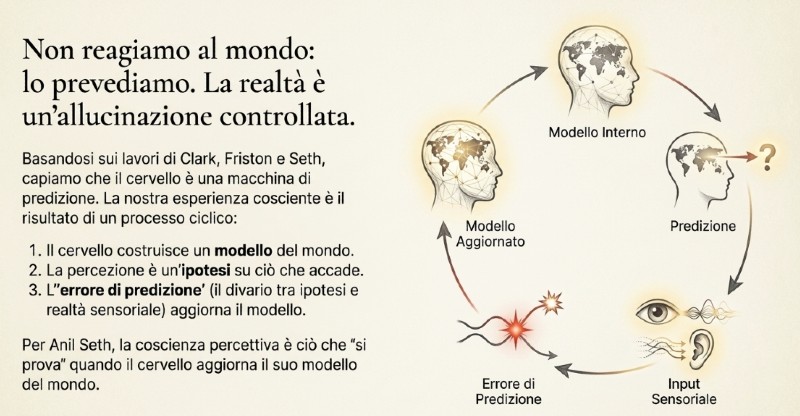
Clark prosegue sulla falsariga di lavori di Karl Friston i quali, a loro volta, sono ripresi da Anil Seth. Quest’ultimo porta il discorso su un livello piuttosto radicale. Secondo Seth la coscienza sarebbe una funzione regolativa del sistema predittivo. Quando il cervello deve bilanciare modelli interni e input sensoriali, la coscienza sarebbe la rappresentazione in prima persona di questo processo di bilanciamento. Cioè:
- La coscienza percettiva è ciò che “si prova” quando il cervello aggiorna il suo modello del mondo;
- La coscienza del sé è ciò che “si prova” quando il cervello aggiorna il modello del corpo e dell’agente che agisce nel mondo.
Nella prospettiva di Clark, Seth e Friston, la coscienza non è “consapevolezza di sé” nel senso riflessivo, ma una forma di percezione incarnata, un continuo atto di sentirsi se stessi nel mondo. “Essere qualcuno” significa avere un modello abbastanza coerente di chi si è, per poter predire cosa succederà dopo.
Secondo il modello del “cervello predittivo”, la coscienza nasce dal flusso costante di previsioni e correzioni che il cervello fa per mantenere il corpo in equilibrio con l’ambiente. Il cervello non rappresenta “un sé astratto”, ma un corpo che agisce e reagisce. Ciò che “sentiamo come io” è, quindi, il risultato di un processo di regolazione predittiva: il cervello anticipa le conseguenze delle azioni corporee e regola le sensazioni interne per mantenere un equilibrio (omeostasi). Quando questa previsione è stabile, emerge il senso di continuità e presenza: “io ci sono”.
Tali tesi sono state applicate in particolar modo nell’ambito delle patologie della mente. Studi come quelli di Charles Fernyhough e Ben Alderson-Day (Durham University) mostrano che:
- Il dialogo interiore è universale;
- Le aree del cervello attivate durante le “voci allucinatorie” sono le stesse di quando pensiamo in silenzio;
- La differenza non è cosa viene percepito, ma come viene attribuito.
In altre parole, la voce interiore e la voce allucinata sono lo stesso fenomeno, ma in un caso la fonte è riconosciuta come interna (“sto pensando”), nell’altro come esterna (“sento le voci”). La differenza sta nella percezione del distacco. Noi non percepiamo la distanza tra il pensiero e il pensatore. Chi ha un’allucinazione uditiva la percepisce, e proprio quella distanza diventa realtà fenomenica.
Questo “distacco del sé” è stato teorizzato anche in filosofia della mente, ad esempio da Thomas Metzinger con l’idea del Self-Model Theory of Subjectivity. Normalmente, il cervello “etichetta” i propri pensieri, le proprie intenzioni e persino le proprie sensazioni motorie come auto-generate. Ad esempio, quando muovi la mano, il cervello anticipa il feedback sensoriale di quel movimento e, quando lo riceve, lo riconosce come previsto. Lo stesso vale per la voce interiore: quando “parli a te stesso” nella mente, il cervello genera una predizione uditiva interna e poi ne sopprime il segnale sensoriale, in modo da non percepirlo come esterno e allucinatorio.
Esperimenti di neuroimaging, in effetti, mostrano che, durante un’allucinazione uditiva, si attivano effettivamente le aree del linguaggio e dell’udito, come se il cervello stesse ascoltando una voce esterna. Ma non c’è nessun input reale: c’è un errore di predizione, un cortocircuito fra ciò che dovrebbe essere previsto e ciò che viene percepito.
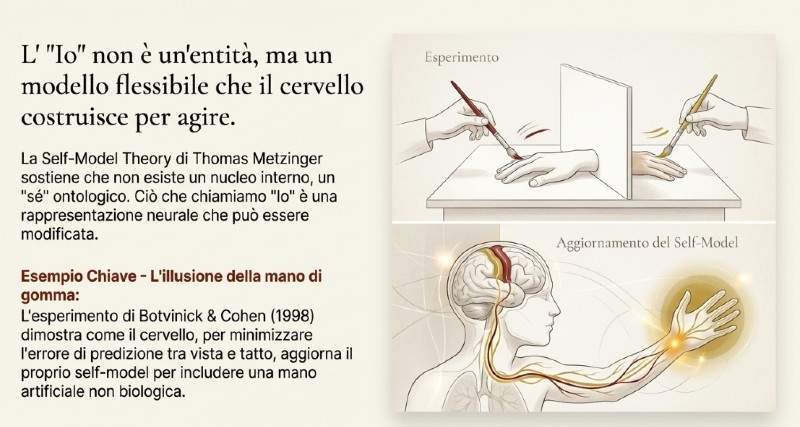
Per Metzinger, quindi, non esiste un sé nel senso ontologico (vedi “Il tunnel dell’io”, testo più divulgativo; oppure “Coscienza e fenomenologia”). Non c’è un nucleo interno, una sostanza cosciente. Ciò che chiamiamo “io” è un Self-Model, cioè una rappresentazione neurale che il cervello costruisce di se stesso come agente nel mondo.
Il classico esperimento di Botvinick & Cohen (1998) - la rubber hand illusion - mostra quanto questo modello sia flessibile:
- Il soggetto vede una mano di gomma davanti a sé;
- Lo sperimentatore tocca simultaneamente la mano vera (nascosta) e quella di gomma;
- Dopo pochi secondi, il soggetto sente che la mano di gomma è la sua.
Il cervello, nel tentativo di minimizzare l’errore di predizione tra input visivi e tattili, ricostruisce il corpo: aggiorna il proprio self-model per includere la mano artificiale.
Metzinger vede in questo esperimento una dimostrazione perfetta della sua teoria: la coscienza non riflette una realtà oggettiva, ma un modello fenomenologico adattivo, che può spostarsi e inglobare elementi non biologici.
In conclusione, la coscienza sarebbe un processo organizzativo, non una proprietà della materia. Cosa che ha implicazioni anche sulla distinzione tra uomo e macchina, che non è più ontologica (biologia vs silicio), ma fenomenologica: dipende da come il sistema vive e si rappresenta.
Lo spostamento della colpa
Se accettiamo le idee di Clark, Metzinger e Seth, l’“io” non è più un’entità unitaria, bensì una modellizzazione interna che integra input corporei, memorie e predizioni sensoriali per generare un senso di continuità. In altre parole, il cervello predice continuamente ciò che accadrà, formula azioni, poi costruisce a posteriori la narrazione del “l’ho deciso io”. Questa è la retro-narrazione del sé, un modo per mantenere coerenza tra percezione e azione.
Metzinger lo dice con chiarezza: “L’esperienza del libero arbitrio è parte del modello fenomenico di sé, non una causa delle azioni”. Quindi, ci sentiamo liberi perché il nostro sistema percettivo deve rappresentarsi come tale, per funzionare in modo coerente. La libertà è un modulo narrativo interno, un’illusione necessaria.
In questo quadro - ovviamente un’ipotesi di lavoro che però ha ottenuto già alcune conferme - l’agire diventa non il risultato di una volontà assoluta, bensì un equilibrio instabile tra sistemi di predizione, retroazione e apprendimento. Ma, se l’agire emerge da sistemi predittivi ibridi dove umano e tecnologico si intrecciano, allora dobbiamo ripensare radicalmente categorie giuridiche fondamentali come responsabilità, colpa e imputabilità.
In un tale contesto la responsabilità non può più essere pensata come un atto che emana da un centro, ma come una proprietà emergente di un sistema distribuito: un intreccio di umani, ambienti e tecnologie che co-producono le azioni.
Con l’avvento dell’intelligenza artificiale, questo intreccio si radicalizza. L’AI non è più solo uno strumento, ma un agente cognitivo capace di influenzare decisioni, percezioni e persino emozioni. Quando un sistema di raccomandazione ci guida, o un LLM suggerisce una decisione, si crea una zona grigia di co-agency: l’azione è umana, ma il percorso che porta a quella scelta è condiviso con una macchina.
Questo sposta la questione della colpa. Non si tratta più di chi ha agito, ma di come l’azione è stata generata da un sistema ibrido. La “colpa” non è più un difetto morale dell’individuo, ma un errore di predizione o coordinazione nel sistema esteso che include l’umano e la macchina. In altre parole, il concetto di colpa diventa funzionale, non più morale: segnala una dissonanza tra i modelli interni (di previsione, di valore) e le conseguenze del mondo reale.

La filosofa Donna Haraway in “A Cyborg Manifesto” anticipa proprio questa svolta. Il soggetto “ibrido” (il cyborg) non è libero nel senso di “autonomo”, ma libero nella misura in cui riconosce e gestisce la propria rete di dipendenze. La responsabilità diventa, così, una responsabilità relazionale, non verso un principio astratto (la legge, la morale), bensì verso le reti di interazione di cui siamo parte. In un’era di automazione sempre più spinta, “essere responsabili” vuol dire sapere come la propria azione si distribuisce, e quindi assumersi la cura dei sistemi che la rendono possibile.
La nostra libertà, in ultima analisi, consiste nel riconoscere di essere parte di una rete di interazioni e nel decidere di mantenere un’etica e un orientamento. La colpa, quindi, non è più morale, ma consiste nel sapere di non essere più un’unità disgiunta, ma una molteplicità in continua negoziazione.
In questo nuovo quadro, dunque, la libertà non è indipendenza, ma trasparenza del proprio grado di interdipendenza; e la responsabilità non è colpa, ma consapevolezza del proprio ruolo nei processi cognitivi e sociali condivisi.
Il soggetto giuridico come costrutto funzionale
Storicamente, il diritto ha sempre costruito il soggetto secondo un modello astratto: un individuo unitario, dotato di volontà e ragione. È il soggetto di Cartesio, di Kant, ma anche del codice civile e penale: chi agisce è colui che decide. Questa impostazione funziona solo se si presuppone una corrispondenza stabile tra mente, corpo e intenzione.
Ma la neuroscienza (Seth, Metzinger) sembra mostrare che questa unità è una simulazione funzionale, un modello interno che serve all’organismo per mantenere coerenza, non una realtà metafisica. Il diritto, quindi, si trova nella posizione paradossale di basarsi su una finzione necessaria: il soggetto come entità autonoma, pur sapendo (filosoficamente e scientificamente) che quella autonomia è in gran parte illusoria.

L’avvento dell’intelligenza artificiale e dei sistemi ibridi “uomo-macchina” rompe questa linearità causale. Non è più chiaro chi agisce. L’azione - pensiamo a un medico che usa un’AI per fare una diagnosi - è il risultato di un processo distribuito (input umani, addestramento, decisioni automatiche, ambiente dinamico). L’intenzione non è più localizzabile: è frammentata tra agenti umani e algoritmici.
Per questo nella teoria giuridica contemporanea si parla sempre più spesso di responsabilità diffusa o condivisa, concetti che derivano direttamente da questa nuova ontologia della soggettività. E tuttavia, il diritto fatica a recepirli pienamente, perché deve pur sempre “imputare” a qualcuno la decisione.
Sia chiaro, il diritto non è vincolato a riprodurre fedelmente la realtà neuroscientifica. Storicamente ha sempre lavorato con “finzioni funzionali”: la persona giuridica, la capacità di intendere e volere, la volontà testamentaria. Queste categorie non descrivono entità naturali, ma costruiscono dispositivi di imputazione che servono a finalità sociali: prevedibilità, deterrenza, riparazione del danno.
La vera domanda, quindi, non è “il sé esiste?”, ma: “dato che operiamo in sistemi ibridi uomo-macchina sempre più complessi, la finzione del soggetto unitario è ancora funzionale agli scopi del diritto?”
Il nesso tra modello predittivo del sé e responsabilità giuridica non è automatico, ma passa attraverso tre considerazioni pragmatiche:
1. Efficacia descrittiva: se l’azione è distribuita tra umano, dati, algoritmi e contesto, cercare un unico colpevole è come cercare “dove sta” un’onda: è una domanda mal posta. Il diritto rischia di sanzionare arbitrariamente, perdendo efficacia.
2. Asimmetria informativa: nei sistemi opachi (deep learning), nessun singolo attore può prevedere o controllare pienamente l’output. Imputare colpa individuale significa punire l’ignoranza strutturale, non la negligenza.
3. Evoluzione tecnologica: con AI sempre più autonome, il modello “comando-controllo” diventa obsoleto. Serve un diritto che governi sistemi che apprendono e cambiano nel tempo, non solo atti puntuali.
In conclusione, i sistemi tecnologici contemporanei rendono il modello della responsabilità individuale progressivamente inadeguato a raggiungere gli scopi del diritto stesso (deterrenza, riparazione, prevedibilità). In questo quadro, il diritto contemporaneo si è incamminato su tre principali linee di risposta:
- Rafforzare la responsabilità umana: riaffermare che l’uomo resta in ultima istanza responsabile delle azioni delle macchine. È l’idea dietro al principio di “human oversight” del Regolamento europeo sull’AI (AI Act). Anche se l’intelligenza artificiale prende decisioni autonome, deve sempre esserci un umano responsabile della supervisione. Questo approccio, però, resta ancorato a una visione antropocentrica: presume che l’umano possa davvero comprendere e controllare il sistema che usa, cosa non sempre vera nei modelli opachi e autoapprendenti.
- Attribuire una responsabilità collettiva: forse ispirandosi alle idee di Seth e Metzinger, alcuni giuristi e filosofi del diritto (es. Gunther Teubner, Mireille Hildebrandt) propongono di considerare i sistemi tecnosociali come reti di responsabilità, dove l’imputazione non è a un soggetto singolo, ma a un insieme di attori (sviluppatori, aziende, utenti, dati, contesto). Qui la colpa non è più un difetto morale individuale, ma una disfunzione sistemica.- Riconoscere soggettività tecniche: una visione post-umanista e più radicale, coerente con la cyborg theory di Haraway e con la self-model theory di Metzinger, sostiene che il soggetto non è chi “è”, ma ciò che “agisce in relazione”. Esplora la possibilità di riconoscere una forma di soggettività limitata alle macchine. Non “diritti umani” alle AI, ma responsabilità funzionali, basate su autonomia operativa e capacità predittiva. Un sistema potrebbe essere trattato come un “agente” giuridico, non perché cosciente, ma perché partecipe di un sistema di decisione che produce effetti sociali reali.
In questo scenario, la responsabilità non è più un atto punitivo, ma un processo riflessivo: un continuo riallineamento tra i modelli interni e il mondo esterno, esattamente come nel cervello di Seth. Il diritto del futuro, se vuole sopravvivere, dovrà evolvere in un diritto della retroazione, quindi:
- capace di correggere errori sistemici,
- di monitorare gli effetti collettivi delle decisioni algoritmiche,
- e di promuovere una responsabilità relazionale, non individuale.
Dal soggetto al sistema: il nuovo diritto europeo
Nel diritto europeo contemporaneo, la transizione dall’idea di responsabilità individuale a quella di responsabilità relazionale e sistemica è già in atto, anche se non sempre dichiarata apertamente.
L’Europa sta costruendo - spesso implicitamente - un nuovo modello giuridico del soggetto postumano, in cui l’“io” non è più un atomo isolato ma un nodo di una rete cognitiva, tecnica e sociale.

Nel GDPR, nel DSA e nell’AI Act si nota un’evoluzione comune. La responsabilità non si fonda più (solo) sull’atto individuale, ma sull’organizzazione dei processi e sull’architettura delle relazioni. Il focus si sposta, quindi, dal “chi ha sbagliato?” al “come si è prodotto l’errore?”, dal “colpevole” al “meccanismo”. Il diritto diventa un sistema di retroazione che tenta di correggere deviazioni predittive, come il cervello di Anil Seth corregge le sue allucinazioni controllate.
Il Regolamento europeo sulla protezione dei dati personali (GDPR) è stato il primo grande laboratorio di questa nuova prospettiva giuridica. Il principio chiave non è più la colpa, intesa come violazione intenzionale, bensì l’accountability - termine spesso impropriamente tradotto con “responsabilità” - che indica una responsabilità relazionale e proattiva.
Nel GDPR il “titolare del trattamento” non è responsabile perché ha sbagliato, ma perché non ha previsto, non ha modellato o non ha corretto adeguatamente i rischi. L’obbligo che si richiede al titolare non è quello di “non provocare danni”, ma di sapere come si producono i danni, cioè come i dati vengono trattati, da chi e con quali effetti. La violazione non è più un atto, ma diventa una mancata sintonia predittiva col sistema socio-tecnico di cui fa parte.
In estrema sintesi, il GDPR trasforma il diritto in una teoria del controllo cognitivo distribuito. Cioè, chi governa i dati deve essere in grado di prevedere e modellare il sistema che li genera ed elabora, e quindi di adattarsi al suo comportamento. È il passaggio dalla “colpa morale” alla “prevenzione sistemica”.
Il DSA (Digital Services Act) amplifica questa logica, spostandola dal dato al discorso. Il tema qui non è la censura o la colpa soggettiva, ma la gestione delle dinamiche di amplificazione e visibilità. La domanda non è più: “chi ha detto la falsità?”, ma “come quel contenuto ha acquisito potere sistemico?”
La responsabilità delle piattaforme diventa, quindi, di mantenere un equilibrio predittivo nel flusso delle informazioni. Ecco perché il DSA introduce:
- La valutazione dei rischi sistemici;
- L’algorithmic trasparency;
- Il crisis response mechanism.
Sono strumenti che servono a riequilibrare la percezione collettiva, a prevenire distorsioni informative e psicosi di rete. In ultima analisi, il DSA sembra tradurre nel diritto l’idea che la coscienza sociale sia una costruzione predittiva distribuita.
L’ultimo strumento normativo europeo che include queste prospettive è l’AI Act. Tramite esso il diritto europeo tenta di governare l’agency ibrida tra umano e macchina, introducendo, come principio cardine (già però presente nel GDPR) il risk-based approach. Qui la responsabilità non dipende da cosa accade, ma da quanto era prevedibile e governabile il comportamento del sistema ibrido. La colpa diventa un errore di progettazione sistemica, non una scelta morale.
Quello che punisce l’AI Act, quindi, non è l’autonomia della macchina, bensì la mancata sintonia tra predizione umana e comportamento algoritmico.
La conclusione è ovvia. Si sta progressivamente passando da una “responsabilità individuale” a una “sistemica”, da una “colpa morale” a una colpa per “mancata previsione”. L’atto illecito diventa il fallimento di un sistema, e il soggetto è il nodo cognitivo in un sistema adattivo. È un diritto che sembra ispirarsi a Metzinger, perché riconosce che il “sé” è un modello funzionale e non una sostanza. Ma anche ad Haraway, perché concepisce il soggetto come ibrido, interdipendente, situato.
Il diritto post-umano
Il diritto che l’Europa sta silenziosamente costruendo non punisce la disconnessione, ma la mancanza di trasparenza relazionale, è un diritto in cui essere liberi non vuol dire agire da soli, ma sapere come si partecipa a una rete di agency condivisa. È un diritto post-umano, dove la colpa non è aver sbagliato, ma aver ignorato la propria interconnessione.

La domanda: “Chi è responsabile se un’AI sbaglia?” non è più solo tecnica o giuridica, ma ontologica. Perché non esiste un centro unitario dell’azione, bensì una rete di cause distribuite che interagiscono tra loro. Il diritto, però, continua ad avere bisogno di un “chi”, e quindi tenta di riconfigurare la responsabilità in senso sistemico, per mantenere la capacità di imputare l’azione.
Il problema centrale non è che le AI sbagliano, ma che non sappiamo come sbagliano. Le AI e gli algoritmi in genere non agiscono secondo regole esplicite, ma apprendono pattern da enormi quantità di dati, sviluppando comportamenti emergenti. Questa opacità genere due effetti:
- Non si può stabilire con certezza chi o cosa ha causato l’errore → interruzione della catena causale;
- Nessuno può dire di aver voluto l’errore, perché nessuno lo ha previsto né compreso pienamente → diluizione dell’intenzione.
È la stessa condizione che, in termini neuroscientifici, separa il “sé esperito” dal “sé agente”. Noi sentiamo di agire, ma l’azione è già in corso prima che ce ne rendiamo conto. Nel diritto dell’AI, quindi, l’agire è collettivo e retroattivo. Solo dopo l’errore si cerca di risalire alla catena di scelte che lo hanno prodotto.
Tre strategie giuridiche

Accountability causale
È l’approccio classico: ricostruire una catena di responsabilità umana. Si analizzano i ruoli (chi ha progettato, addestrato, integrato e utilizzato) per verificare chi poteva intervenire e non lo ha fatto. Questi risponde in base al principio del controllo effettivo. Si tratta dell’approccio strutturato in prevalenza in Europa (AI Act e diritto civile): le imprese devono dimostrare di aver adottato “misure adeguate” di prevenzione, test e sorveglianza.
Il limite sta nel fatto che è una responsabilità retrospettiva e limitata, in quanto non coglie la natura emergente dei sistemi che cambiano comportamento nel tempo (come, appunto, le AI soggette a feedback).
Responsabilità sistemicaSembra ispirata direttamente al modello relazionale che abbiamo descritto più sopra. Qui l’unità di imputazione non è più il singolo, bensì il sistema socio-tecnico nel suo complesso (sviluppatori, utenti, dati, infrastruttura, logiche di mercato). L’idea è che il danno non derivi più da un atto singolo, ma da una configurazione di interazione, ad esempio un bias nei dati, pessime scelte di progettazione, oppure errate metriche di ottimizzazione.
In questo quadro, la colpa è diffusa, ma non dissolta:
- a ogni nodo si attribuisce una quota di responsabilità in base alla posizione nel sistema;
- il focus è sulla responsabilità di rete, non sull’interazione individuale;
- il fine non è punire, ma correggere il sistema.
Ecco che il diritto diventa un meccanismo di feedback adattivo. Come in un cervello, l’errore non è una colpa, ma un segnale da integrare nel ciclo di apprendimento collettivo. Lo scopo non è, appunto, punire, ma ridurre l’errore.
Questo modello emergente introduce una logica quasi “cognitiva” nel diritto. L’obiettivo è di anticipare il rischio di errore prima che accada, attraverso sistemi di audit, valutazione del rischio e tracciabilità algoritmica. È un diritto che non punisce, ma “prevede”. Potremmo dire che si ispira direttamente all’idea di “cervello predittivo” di Anil Seth.

Gli esempi concreti sono già tra noi:
- DPIA (Data Protection Impact Assessment) nel GDPR
- Risk Classification e obbligo di Human oversight nell’AI Act (maggiore è il rischio più profondo deve essere l’audit)
- Valutazione dei rischi sistemici e trasparenza sugli algoritmi nel DSA (le piattaforme di grandi dimensioni devono sottoporre i propri algoritmi ad audit indipendenti annuali, per verificare la gestione dei rischi sistemici come disinformazione, manipolazione, diritti fondamentali).
In tutti questi casi la responsabilità è predittiva, non reattiva. Quello che si chiede è di “sapere come potrei sbagliare”. E in questo senso è la direzione più coerente con la visione neuroscientifica dell’essere umano come sistema di previsioni che si aggiornano costantemente per ridurre l’errore.
Nel diritto dell’AI emergente, la colpa non è più sinonimo di dolo o negligenza, ma di disallineamento tra modelli mentali e mondo reale. Un sistema diventa “colpevole” se:
- non riconosce i propri limiti predittivi,
- non aggiorna le sue rappresentazioni dopo un errore,
- o ignora le retroazioni provenienti dal suo ambiente.
Ed è lo stesso meccanismo che vediamo con la schizofrenia o la dissonanza cognitiva estrema. Se un cervello perde la capacità di integrare i feedback, genera allucinazioni. Un sistema legale che non si aggiorna funziona allo stesso modo: inizia ad allucinare giustizia.
La logica è che non esistono più confini netti tra agente e ambiente, e l’etica consiste nel mantenere l’allineamento tra sé e il mondo. Il diritto dell’AI:
- non attribuisce colpe in senso punitivo;
- mantiene trasparenza cognitiva tra uomo, macchina e ambiente normativo.
Ecco perché le piattaforme (Meta, Google, Microsoft, OpenAI, Amazon) hanno introdotto modelli di accountability multilivello, volti a rendere tracciabile il processo decisionale del sistema. L’audit algoritmico, in questo quadro, rappresenta una forma di meta-consapevolezza esterna (in senso metzingeriano), è un modello del sistema costruito per vedere come il sistema si vede. È un’operazione di self-modeling tecnico in cui si tenta di rendere esplicito ciò che, di natura, è opaco. Ad esempio:
- OpenAI System Cards: descrivono l’intento, i limiti, i rischi, i dati e le mitigazioni dei modelli;
- Google Responsible AI Toolkit: introduce l’audit etico, basato su principi di fairness, explainability e interpretability;
- Meta AI Governance Framework: adotta un sistema di risk tiering, che collega l’impatto potenziale del modello a diversi livelli di sorveglianza interna e reporting;
- Microsoft Responsible AI Standard: impone un Impact Assessment prima del deployment di qualsiasi modello ad alto rischio.
L’audit, in ultima analisi, non serve solo a dimostrare la conformità, ma anche a costruire un corpo normativo vivente che evolve insieme al modello. In questo modo le piattaforme introducono cicli di revisione continui, adottano comitati di revisione umani e sperimentano forme di trasparency reporting automatizzato per consentire verifiche ex post.
Il sistema complesso “AI+umano”, in questo modo, sviluppa una forma di embodiment normativo: il modello percepisce sé stesso attraverso strumenti di audit, e gli umani si incarnano nelle sue decisioni attraverso la tracciabilità e il feedback. La responsabilità, quindi, non è più localizzata, ma diffusa e incarnata in una rete di osservazione reciproca.
Quello che emerge con evidenza è che il dibattito sulla personalità giuridica delle AI sembra nascere proprio dal tentativo di tradurre in diritto ciò che, sul piano filosofico, autori come Metzinger e Haraway avevano anticipato: la dissoluzione dei confini tra umano, tecnico e collettivo.
Dalla finzione giuridica alla soggettività funzionale
Nel diritto la personalità giuridica è sempre stata una finzione utile. Non solo gli esseri umani, ma anche le società, le fondazioni, i trust, sono soggetti di diritto perché è utile che lo siano per poter attribuire responsabilità, stipulare contratti e rispondere dei danni causati. Ma oggi, di fronte ad AI autonome, il diritto si trova davanti a un paradosso: un sistema può agire nel mondo stipulando contratti, prendendo decisioni mediche o economiche, causando danni, senza che vi sia un agente umano diretto.
Da qui la proposta discussa (ma non accolta) del Parlamento europeo nel 2017 di introdurre una personalità elettronica limitata per i sistemi autonomi. La Risoluzione del Parlamento Europeo (2017/2103(INL)) prevedeva di introdurre un electronic personhood per i robot più avanzati, simile a una responsabilità patrimoniale separata, sul modello delle persone giuridiche. L’idea era:
- il sistema AI dispone di un fondo o assicurazione dedicata,
- e risponde dei danni che produce,
- mentre i creatori e gli utilizzatori restano responsabili solo entro certi limiti.
Ma la proposta suscitò un’ondata di critiche, sia etiche che giuridiche. Il Comitato Europeo per l’Etica delle Scienze (EGE) dichiarò sostanzialmente che attribuire personalità a una macchina “minerebbe la dignità umana”, poiché suggerirebbe un’equivalenza ontologica tra umano e artefatto. Studiosi sottolinearono che la personalità giuridica avrebbe potuto essere dannosa in quanto avrebbe potuto “annacquare” le responsabilità umane.
Nel Libro Bianco sull’AI (2020) la Commissione Europea abbandona, quindi, l’idea di una personalità elettronica e punta invece su un approccio risk-based e collettivo: l’attenzione si sposta dalla macchina al suo ecosistema. Il fulcro non è lo status giuridico della macchina, ma la catena di responsabilità lungo l’intero ciclo di vita del sistema: sviluppatori, fornitori, utilizzatori e autorità di controllo. Le misure proposte riguardano governance dei dati, valutazione d’impatto, sorveglianza del mercato, ruoli dei diversi attori e coordinamento tra Stati membri, cioè l’“ecosistema di eccellenza” e l’“ecosistema di fiducia”.
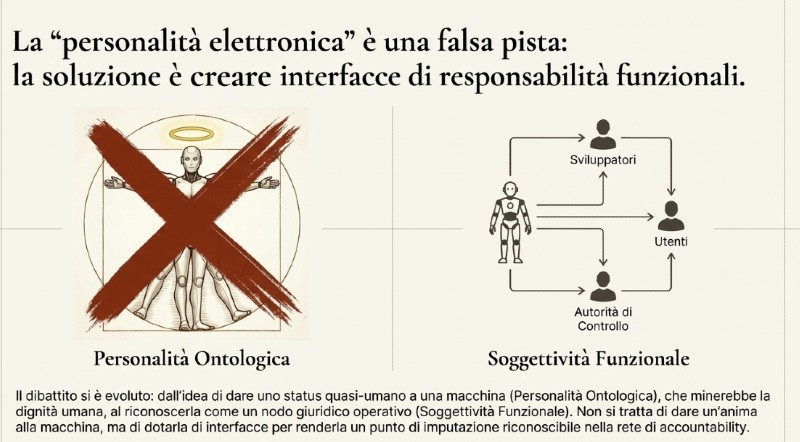
Si è passati, quindi, alla personalità giuridica operativa o strumentale, non più ontologica: un modo per governare l’autonomia tecnica, senza dissolvere la responsabilità umana. Questo non significa riconoscere un’anima alla macchina, ma dotarla di interfacce giuridiche funzionali, come la capacità di stipulare contratti, di operare sotto licenza, ecc.
Le prime applicazioni non hanno tardato. La Stanford Center for Legal Informatics o la Cambridge AI Ethics Lab stanno già sperimentando forme di AI legali con status limitato, specialmente in ambito contrattuale o societario:
- Smart entities che possono firmare e gestire contratti automaticamente;
- AI fiduciaries, che amministrano fondi o gestiscono dati per conto di un soggetto umano, ma con autonomia operativa;
- DAOs (Decentralized Autonomous Organizations), già riconosciute in alcuni Stati USA (come il Wyoming) come soggetti giuridici ibridi, con capacità patrimoniale propria e governance algoritmica.
Col riconoscimento di una personalità funzionale limitata all’AI non facciamo altro che riconoscere l’emersione di un nuovo livello di agency, non biologico ma, appunto, funzionale. Haraway lo aveva predetto: il cyborg, l’ibrido uomo-macchina, il sistema complesso AI+uomo, rompe gli schemi e la distinzione tra organismo e macchina. Il diritto cerca di ricucire quel confine con un nuovo tessuto normativo. Non si tratta di attribuire un’anima all’AI, bensì di costruire una matrice di accountability, una forma di embodiment giuridico, un modo per dare al sistema una voce riconoscibile nelle reti di decisione.
In questo quadro l’AI Act è il fulcro del diritto dell’AI. Non parla mai esplicitamente di personalità elettronica, ma di fatto ne gestisce le conseguenze. Ogni sistema di AI deve essere inscritto in una catena di responsabilità umana (sviluppatori, deployer, utenti, fornitori di dati) che ne garantisce trasparenza, controllo ed etica. La macchina agisce, ma i suoi “sensori” legali (audit, log, oversight) rimandano continuamente alle persone fisiche o giuridiche. L’AI non ha, quindi, una personalità, ma è costantemente circondata da un corpo normativo che la rende trasparente e quindi controllabile.
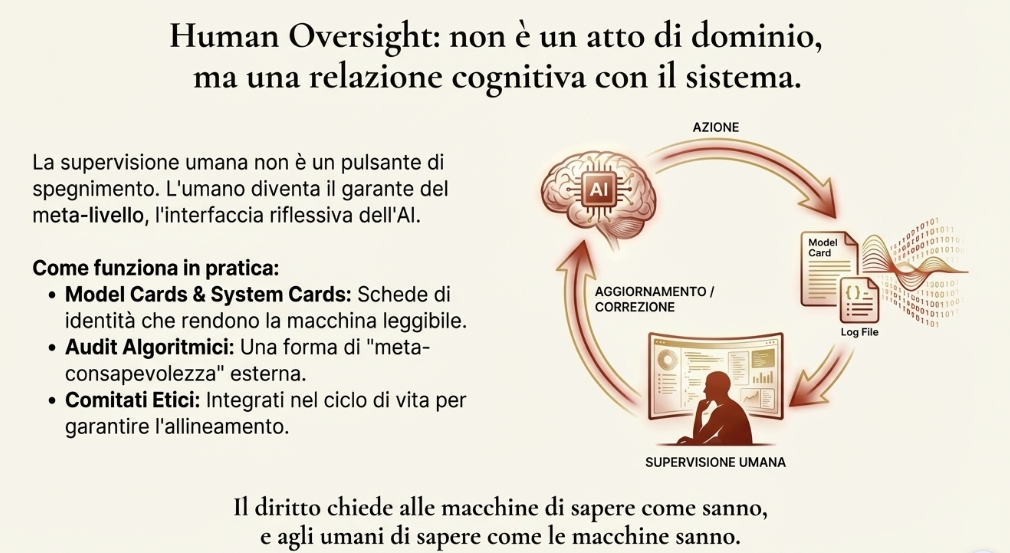
In questo senso il principio di human oversight (artt. 14 e 29) diventa una vera e propria filosofia dell’ibridazione: il controllo non è atto di dominio dell’uomo sulla macchina, bensì una relazione cognitiva reciproca, in cui l’umano diventa parte della rete, l’interfaccia riflessiva dell’AI. Non si tratta, quindi, di umanizzare la macchina, ma semplicemente di creare un soggetto giuridico funzionale capace di essere destinatario di obblighi normativi, di disporre di risorse economiche dedicate (assicurazioni) e agire come nodo autonomo nella rete di accountability. Questa nuova figura consente di chiudere la catena di imputazione senza dissolvere la responsabilità umana.
Nella pratica lo Human Oversight viene applicato tramite le Model Cards, introdotte da Google nel 2019 e ormai adottate da tutte le Big Tech. Sono schede di identità trasparenti che descrivono l’uso previsto del modello, i dati di addestramento, le metriche di performance e i limiti di impiego e i rischi noti. Ciò consente di rendere la macchina leggibile e interpretabile per chi la supervisiona. A ciò si aggiungono archivi pubblici di “incidenti algoritmici” al fine di creare un sistema dove ogni errore diventa conoscenza condivisa. La logica, perfettamente aderente all’AI Act, è di rendere l’ecosistema capace di apprendere dai fallimenti. Infine, abbiamo i comitati etici interni integrati nel ciclo di vita dei prodotti.
Tutto ciò contribuisce a creare una catena di revisione multilivello che lega scienziati, giuristi e designer in una vasta rete di responsabilità, e nel quale l’umano è garante del meta-livello, non dell’azione singola. Il nuovo diritto nell’epoca dell’AI chiede alle macchine di sapere come sanno e agli umani di sapere come le macchine sanno.

Appendice – Stato scientifico delle teorie citate
Le idee di Andy Clark, Karl Friston, Anil Seth e Thomas Metzinger non sono speculazioni astratte, ma modelli scientifici e filosofici oggi molto influenti nelle neuroscienze e nella filosofia della mente. Tuttavia, differiscono per grado di conferma empirica e per ambizione teorica.
Una premessa necessaria: cosa sappiamo (e non sappiamo) sulla coscienza
Nonostante le neuroscienze abbiano fatto progressi enormi nella comprensione dei processi percettivi, dell’integrazione sensoriale e dei meccanismi decisionali, la natura ultima della coscienza rimane un problema irrisolto. Non esiste un consenso su come e perché l’attività neuronale dia luogo all’esperienza soggettiva in prima persona.
Le teorie citate in questo articolo non pretendono di spiegare “che cos’è” la coscienza. Si concentrano, invece, su come il cervello costruisce modelli del mondo e di sé, offrendo una cornice utile per comprendere percezione, agency e comportamento. Devono essere intese, quindi, solo come strumenti interpretativi; robusti sicuramente, ma non verità definitive sull’essenza della coscienza.
1. Predictive Processing / Active Inference (Clark, Friston)
È uno dei modelli neuroscientifici più accreditati a livello internazionale. Descrive il cervello come un sistema di predizione che minimizza l’errore tra modelli interni e input sensoriali.
Supportato da numerosi dati sperimentali (fMRI, MEG, illusioni percettive, disturbi mentali).
→ Considerato un paradigma solido, anche se non definitivo.
2. Coscienza come percezione controllata (Anil Seth)
Applica il predictive processing alla percezione del sé corporeo e alla coscienza percettiva.
Supportato da studi su embodiment, interocezione e disturbi dissociativi.
La parte fenomenologica rimane una formulazione interpretativa.
→ Modello plausibile e coerente con le evidenze, ma non conclusivo.
3. Self-Model Theory (Thomas Metzinger)
Teoria filosofica che interpreta il sé come una modellizzazione neurale generata dal cervello.
Compatibile con molti risultati neuroscientifici (illusioni corporee, agency, allucinazioni).
Le tesi metafisiche (es. “il sé non esiste”) sono ancora oggetto di dibattito.
→ Molto influente, ma più speculativa delle precedenti.
In sintesi
Le teorie citate sono oggi tra le più rilevanti nel dialogo tra neuroscienze, filosofia e scienze cognitive. Sono modelli interpretativi avanzati, fondati su dati e sperimentazione, che offrono strumenti utili per descrivere l’agire umano e la distribuzione della responsabilità nei sistemi complessi. Ma non risolvono il mistero della coscienza: chiariscono come il cervello costruisce un sé coerente, non cosa sia in ultima analisi l’esperienza cosciente.




